

1. 서 론
1.1. 연구 배경
1.2. 연구 범위
2. 연구 방법
2.1. 체계적 문헌 조사를 통한 대상 문헌 선정
2.2. LLM의 자동 문헌분류 성능평가
3. 연구 결과
3.1. 도출된 BEMS 관련 연구 문헌
3.2. 제로샷 프롬프팅에 따른 연구 문헌 분류 결과
3.3. 제로샷 방식의 문헌분류 성능 평가
3.4. 퓨샷 프롬프팅에 따른 연구 문헌 분류 결과
3.5. 퓨샷 방식의 문헌분류 성능 평가
3.6. Fleiss’ Kappa와 Gwet’s AC1 산출결과
4. 논 의
4.1. 연구자 간의 연구문헌 분류 적합성 평가 차이 원인
4.2. LLM as a judge에 의한 분류의 방법론적 시사점
4.3. Fleiss’ kappa 활용의 한계
4.4. 평가자 선정과 인원 수의 한계
5. 결 론
1. 서 론
1.1. 연구 배경
2022년 말 ChatGPT의 출시를 시작으로 하여 대규모 언어 모델(LLM, Large Language Model)의 활용이 급증하고 있다. 대규모 언어모델은 복잡한 코딩 없이 자연어 기반 프롬프트만으로 학습된 모델과 상호작용을 가능하게 하는 것이 특징이다. 이러한 LLM 의 편의성으로 인해 일반인이 느끼는 AI에 대한 접근성이 크게 향상되었다. 또한, LLM은 단순한 텍스트 생성 기능을 넘어서 비정형 데이터 이해, 논리적 추론, 핵심 정보 요약 등 고도화된 데이터 처리 능력을 갖추게 되었다. 이러한 발전은 LLM 모델을 학술 및 연구 분석 분야에서도 활용가능하게 하고 있다. 한편, 국내 BEMS(Building Energy Management System) 연구는 최근 5년간 급증하며 스마트 빌딩, 에너지 절감 기술, 제어 알고리즘 등 다양한 주제로 확장되고 있다. 그러나, 연구가 복잡하게 분화될수록 연구 문헌에 대한 기존의 키워드 분석·수동 분류 방식은 빠른 기술변화의 맥락과 연구 동향의 질적 변화를 충분히 반영하지 못하는 한계를 가진다.
이러한 문제의식 속에서 주목되는 LLM as a Judge 방법론은 연구 문헌의 분류에 있어 주목할 만하다(Gu et al., 2024). 이 방법은, LLM을 인간 대신 평가의 주체로 활용하는 방법이다. 이 방법은 전문가 평가를 대신할 수 있으며, 다량의 평가를 짧은 시간 안에 평가할 수 있다는 장점이 있다. 그러나 인간 평가와의 간극은 존재하며, 이를 줄이는 것이 LLM as a Judge로서의 정확도를 높이는데 매우 중요한 관건이다.
이러한 맥락에서, BEMS 관련 문헌의 자동 분류에 있어, LLM의 활용은 작업 효율을 높이는 유용한 도구가 될 수 있다. 따라서, 본 연구에서는 최근 BEMS와 관련된 연구 내용에 따른 자동 분류 작업에 있어 LLM의 활용 가능성을 평가하고자 한다.
1.2. 연구 범위
본 연구에서는 BEMS 관련 문헌의 내용적 분류에 있어, LLM의 활용 가능성을 평가하는 것을 목표로 한다. 이를 위해 체계적 문헌 분석을 통한 BEMS 관련 연구 문헌 추출, 클라우드 기반 LLM 모델인 ChatGPT-5.1 모델을 이용한 BEMS 관련 문헌의 분류 및 이에 대한 연구자 평가의 과정을 거친다.
LLM 모델을 이용한 BEMS 관련 문헌의 분류 시, LLM 모델의 입력 방식과 관련된 프롬프팅 기술을 활용하였다. 먼저, LLM 모델의 자체 성능을 확인하기 위한 Zero-shot 방식과, 약간의 예시를 주는 Few-shot 방식이 적용되었다. 이후, LLM 모델의 분류 결과에 대한 연구자 평가는 본 연구를 기획한 건축공학부 학부생 참여 연구자 4인이 평가하였다. 이는 일정 수준으로 훈련된 전공자를 LLM as a judge로서의 성능 평가에 활용할 수 있는지의 가능성을 검토하고자 하는 목적을 포함한다. 최종적으로는 LLM 모델의 분류 성능에 대한 연구자 평가의 최종합의율을 도출하였다. 이후 연구자들 간의 평가 일치도를 확인하기 위해 Fleiss’ kappa 및 Gwet’s AC1을 평가하였다.
2. 연구 방법
2.1. 체계적 문헌 조사를 통한 대상 문헌 선정
본 연구는 국내 BEMS 및 건축물 에너지관리 분야의 문헌을 대상으로 LLM as a Judge 방식의 문헌 분류 작업의 신뢰도를 파악하는 것을 목표로 한다. 이에 따라 대상 연구문헌을 체계적 문헌 조사를 통해 선정하는 작업을 우선적으로 수행하였다. 조사 문헌은 출판일 기준으로 2021년 1월 1일부터 2025년 11월 20일까지의 최근 5개년으로 설정하였다. 문헌 수집은 DBpia 학술 데이터베이스를 활용하여 수행하였다. BEMS 주제와 관련된 논문을 추출하기 위해 BEMS, 건물에너지관리시스템, 빌딩에너지관리시스템, Building Energy Management System이라는 4가지 키워드만을 선정하여 검색을 수행하였다. 또한, 백색문헌만을 선정 대상으로 하여, 정식 학술지에 게재된 연구논문만을 대상으로 선정하였다. 학위논문, 학술발표대회 논문, 연구보고서 등과 같은 회색문헌은 연구의 엄밀성을 유지하기 위해 제외하였다. 또한 초기 수집된 문헌 중 BEMS와 연관성이 낮거나 연구 주제와의 적합성이 떨어지는 자료, 중복 문서 등은 체계적 문헌 조사 과정에서 배제하였다.
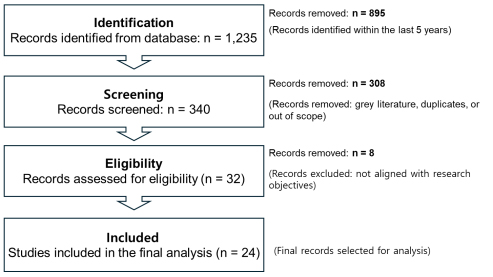
먼저, DBpia 학술 데이터베이스에서 BEMS 관련 4가지 키워드를 기반으로 최근 총 1,235편에 해당하는 문헌을 1차 추출하였다. 5년 동안의 학술 논문만을 선정한 결과 340편의 논문이 추출되었다. 그리고 학술저널(white literature)만을 선별하여 32편의 연구 문헌이 선정되었으며, 연구 주제와 적합성이 낮거나 중복되는 문헌을 제거하여 최종적으로 24편의 문헌이 분석 대상으로 추출되었다. 전체 프로세스는 Figure 1과 같다.
2.2. LLM의 자동 문헌분류 성능평가
본 연구는 체계적 문헌조사를 통해 선정된 BEMS 관련 논문을 대상으로 LLM as a Judge 기법을 활용한 자동 분류 기법을 적용하였다. 문헌자료 분류는 LLM 모델인 ChatGPT-5.1 을 활용하였다. 이후 연구자 4인(Human Judge)이 분류 결과를 적합(O), 부적합(X)으로 검토하였다. 이를 통해 대규모 언어모델(LLM)의 문헌 분류가 적절한지를 평가하였다.
이때 LLM 분류 단계는 두 가지 방식으로 적용되었다. 먼저, 사전에 어떠한 기준도 제공하지 않고 모델의 추론 능력을 평가하기 위한 제로샷(Zero-shot) 방식과, 연구자가 사전에 정의한 분류 기준을 제시한 후 수행한 퓨샷(Few-shot) 방식이 각각 독립적으로 적용되었다. 이러한 방식 비교를 통해 두 접근법 간 분류 결과의 정확도 및 활용 가능성을 검토하고, LLM 기반 연구동향 분석 기법의 적용 가능성을 평가하였다. 본 연구에서는 문헌 분류 체계의 절대적 ‘true’ 값을 별도 설정하지 않았으며, 대신, 평가자 4인의 합의율이 75%이상이 되는 경우를 합의에 기반한 기준값으로 설정하였다. 이에 따라, 제로샷과 퓨샷의 분류 결과를 해당 기준값과 비교하여 제로샷과 퓨샷의 방법론적 성능 차이를 비교하였다.
제로샷 방식으로 문서의 분류를 수행하기 위해 LLM에 논문명, 초록을 입력하였다. 그리고 이를 기반으로 LLM이 자율적으로 문서 분류 체계를 출력하도록 하였다. 퓨샷 방식의 단계에서는 연구자가 먼저 생성한 연구 분류 체계를 입력하고, 이에 따라 LLM이 연구 문헌을 분류하게 하였다. 입력 자료는 제로샷 방식과 동일하게 논문명과 초록이 활용되었다. 이후 LLM이 생성한 문헌자료 분류 결과의 타당성을 검토하기 위해, 4명의 연구자는 논문명과 초록을 기반으로하여 다음 세 가지 기준에 따라 검토를 실시하였다. 각 연구자는 서로 합의 없이 독립적으로 평가를 실시하였다.
① 카테고리와 논문 내용 간의 일치성
② 카테고리 내 연구방법론의 유사성
③ 카테고리 간 주제 중복 여부
연구자는 논문과 카테고리의 내용이 명확히 부합하거나 중복 분류가 가능한 경우에는 “O”, 부합하지 않을 경우에는 “X”로 표시하였다. 이후 연구자들의 평가 결과에서 도출된 적합(O), 부적합(X)의 개수를 강한 다수결의 최종 합의율을 산정하여 종합적인 평가결과를 계산하였다. 최종 합의율은 연구자가 제시한 식 (1)에 의해 계산된다. 한편, 본 연구에서는 우연적 일치 가능성을 최소화하고 분류 결과의 안정성을 확보하기 위한 보수적 기준으로 75% 합의율을 적용하였다. 이는, 4인 평가 구조에서 2인의 동의(50%)는 의견이 절반으로 나뉘어 판단의 안정성을 담보하기 어려운 반면, 3인 이상의 동의(75%)는 단순 과반수를 넘어 집단 판단의 일관성이 확보되었음을 뜻한다고 보았기 때문이다. 동시에 기존 문헌에서 가장 빈번하게 사용하는 합의율이 75%라는 결과도 참조하였다(Diamond et al., 2014).
FAR: final agreement rate(%)
NP: number of papers rated as appropriate by minimum 3 researchers
TP: Total number of papers
마지막으로, LLM의 분류 결과와 연구자 판단 간의 일치 수준을 검증하기 위해 Fleiss’ kappa와 Gwet’s AC1을 활용하였다. Fleiss’ kappa는 세 명 이상의 연구자가 여러 범주에 대해 판단한 결과의 일관성을 정량적으로 평가하는 지표이다. Fleiss’ kappa의 값은 1에 가까울수록 연구자 간의 일치도가 높다는 것을 의미한다. 최종 합의율과 Fleiss’ kappa가 높은 것은 연구자 간의 일치도가 높은 분류 결과와 LLM 분류 결과가 매우 유사함을 의미한다. Fleiss’ kappa는 식 (2), (3), (4), (5), 식 (6)을 이용해 산출된다.
: Fleiss’ kappa
N: number of subjects/items being rated
n: number of ratings per subject (assumed constant)
k: number of possible rating categories
nij: number of raters who assigned the i-th subject to the j-th category
: Mean observed agreement
: Expected agreement by chance
한편, Fleiss’ kappa 계수는 우연에 의해 판단이 일치할 가능성을 보정하기 위해 범주에 대한 선택 확률을 기반으로 신뢰도를 산정한다(Fleiss, 1971; Landis & Koch, 1977). 그러나 특정 범주에 평가자의 선택이 집중되는 경우, 실제로는 평가자 간 일치도가 높음에도 불구하고 우연에 의한 일치 확률이 과도하게 크게 산정되어 전체 신뢰도가 낮게 평가될 수 있는 한계가 존재한다. 즉, 분류에 대한 연구자 평가 결과가 O, X 중 한쪽 범주로 편중될수록 kappa 계수는 실제 합의 수준을 충분히 반영하지 못하는 경향을 보인다. 이에 비해 Gwet’s AC1은 Fleiss’ kappa 계수와 유사한 구조를 따르지만, 우연 일치도 산정 방식에 있어서 범주 편중의 영향을 완화하도록 설계된 지표이다(Gwet, 2008). 이 지표는 평가자들이 동일한 판단을 반복적으로 내리더라도, 이를 단순히 우연의 결과로 간주하지 않고, 실제로 합의가 형성되었음으로 반영하여 보다 안정적으로 신뢰도를 산출하도록 설계되었다. 그 결과, 관찰된 일치도가 특정 범주에 집중된 상황에서도 분류 결과의 신뢰도를 보다 합리적으로 평가할 수 있다.
: expected agreement (for AC1)
본 연구에서는 이러한 두 가지 지표를 동시에 활용하여 연구자 4인이 수행한 LLM 분류 결과에 대한 평가를 수행하였다. 이를 통해 LLM을 활용한 문헌 분류 결과가 인간 판단과 유사한 수준의 성능을 보이는지 확인하였다. 동시에 인간 연구자의 평가 결과가 정답(golden set) 또는 참조기준(reference)로서 요구되는 일관성을 적절히 확보하였는지 검토하였다.
3. 연구 결과
3.1. 도출된 BEMS 관련 연구 문헌
본 연구에서 체계적 문헌 조사를 통해 수집된 문헌은 총 24개 문헌이며, 세부 내용은 다음 Table 1과 같다. Table 1에서는 연구 제목을 제시하고 있으며, 이는 LLM 모델인 ChatGPT-5.1에 입력되었다. 동시에, 해당 연구 문헌의 초록 역시 입력자료로 활용되었다.
Table 1
Selected Papers Identified through a Systematic Literature Review
| No | Authors | Year | Title |
| 1 | Quan et al. | 2021 |
A Study on Energy Consumption Prediction from Building Energy Management System Data with Missing Values Using SSIM and VLSW Algorithms |
| 2 | Jeon & Kim | 2025 |
A Study on Recovering Lost Data of Office Building Electric Power Consumption using Outdoor Air Enthalpy Variation Patterns |
| 3 | Lee et al. | 2025 |
Analysis of BEMS Applicability in Existing Multi-family Housing Based on Facility and Communication Infrastructure |
| 4 | Bae & Song | 2024 |
A Study on the Development of BACnet-based System Control Application Using RTU Terminal. |
| 5 | Jung et al. | 2020 |
An Empirical Study on the Validity of the Construction Project of Overseas Public Building Energy Management System |
| 6 | Choi | 2025 | Analysis of Standard Trends and Standardization of Energy Management Systems. |
| 7 | Kim et al. | 2020 | Improvements on Public Buildings Energy Information System |
| 8 | Oh et al. | 2025 |
Comparative Study of System Capacity Based on Renewable Energy Installation Standards in Korea |
| 9 | Choi et al. | 2025 |
Analysis of Korea’s Building Energy Codes and Certification Systems for the Implementation of the Grid-Interactive Efficient Building (GEB) |
| 10 | Ahn & Jung | 2022 |
Trends in ICT-Based Building Energy Management Technology Standardization for Carbon Neutrality |
| 11 | Lee & Jung | 2021 | Design of IoT-based Energy Monitoring System for Residential Building |
| 12 | Ra et al. | 2020 |
Analysis of Annual Operation Status of Central Heating and Cooling System in a Public Office Building |
| 13 | Hwang et al. | 2024 | Building Energy Efficiency through the Application of Digital Twin-based BEMS |
| 14 | Ahn et al. | 2020 |
Predicting Supply Air Temperature in Air Handling Unit Using Machine Learning-Based Automation Algorithm |
| 15 | Kim & Kim | 2022 |
Reinforcement Learning-Based Illuminance Control Method for Building Lighting System |
| 16 | Yun et al. | 2025 |
Development and Data-Driven Evaluation of Internal Heat Gain Prediction-Based MPC for HVAC Systems |
| 17 | Choi et al. | 2023 |
Predicting Model Energy Consumption in Multi-Family Homes During the Summer Period Measured by BEMS (Building Energy Management Systems) Using the SARIMAX (Seasonal Auto-Regressive Integrated Moving Average with eXogenous factors) Model |
| 18 | Kim et al. | 2024 |
Performance Comparisons on Learning Based Prediction Models Considering Electricity Demand Patterns of Buildings |
| 19 | Jung et al. | 2021 |
An Empirical Study of Building Energy Consumption Prediction Simulator Using Machine Learning Techniques |
| 20 | Lee et al. | 2020 |
Prediction and Evaluation for Power of Photovoltaic system based on Dynamic Time Warping Hierarchical Clustering for Building Energy Management |
| 21 | Choi & Kim | 2025 |
Reinforcement Learning Based Energy Control Method for Smart Buildings Integrated with Renewable Energy |
| 22 | Park et al. | 2022 |
A Study on EMS Operation Algorithm for Peak Demand Management of Small Zero Energy Building |
| 23 | Choi et al. | 2022 |
An Analysis of Energy Consumption Characteristics and Energy Self‐sufficiency Rate of National Park Management Offices Using BEMS Data |
| 24 | Lee et al. | 2025 |
Performance Analysis of BIPV System and Power Consumption Modeling with ESS Integration in a Library Building |
3.2. 제로샷 프롬프팅에 따른 연구 문헌 분류 결과
본 연구에서 선정된 24편의 문헌에 대한 ChatGPT-5.1의 제로샷 분류 결과는 일곱 가지로 나타났다. 해당 분류는 ① BEMS 데이터 품질 관리·결측 복원 ② BEMS 인프라·플랫폼 및 적용성 ③ IoT·센서 기반 에너지 모니터링 ④ 설비 운전 데이터 기반 성능·운영 분석 ⑤ 설비·시스템 제어 및 운영 최적화 ⑥ 에너지 소비 분석·예측 ⑦ 재생에너지·에너지 자립·연계형 운영이다. 제로샷 프롬프팅에 의해 분류된 연구 논문 목록은 Table 2에 제시되어 있다.
Table 2
Zero-Shot Classification Results Generated by ChatGPT-5.1
*Paper numbers are consistent with those presented in Table 1.
먼저 BEMS 데이터 품질 관리·결측 복원 분야에는 Quan, Shin, Ko와 Shin (2021)와 Jeon과 Kim (2025) 가 포함되어, 데이터 결함을 보완하기 위한 알고리즘을 제시한다. BEMS 인프라·플랫폼 및 적용성 분석 분야에는 Lee, Kim, Kim과 Kim (2025), Bae과 Song (2024), Jung, Kim, Kim과 Shin (2020), Choi(2025), Kim, Oh, Yang과 Lee (2020), Oh, Chae와 Nam (2025), Choi 등(2025), Ahn과 Jung (2022) 등이 해당되며, BEMS 기반 시설·플랫폼 구축 환경과 제도적 기반을 폭넓게 다루었다. IoT·센서 기반 에너지 모니터링 분야에는 Lee와 Jung (2021)이 포함되며, 실시간 전력계측 기술을 활용한 모니터링 시스템을 제시한다. 설비 운전 데이터 기반 성능·운영 분석 분야에는 Ra, Aum과 Son (2020) 이 포함되어, 실제 운전 데이터를 통해 냉난방 시스템 효율과 문제점을 분석하였다. 설비·시스템 제어 및 운영 최적화 분야에는 Hwang, Kim과 Yun (2024), Ahn, Hong과 Kim (2020), Kim과 Kim (2022), Yun, Ryu와 Seo (2025)이 포함되며, 기계학습·강화학습 등의 전략을 통해 에너지 운영 효율을 향상시키는 연구들로 구성된다. 에너지 소비 분석·예측 분야에는 Choi, Lee와 Kim (2023), Kim, Kim, Lee와 Kim (2024), Jung, Kim, Lee와 Kim (2021) 이 포함되며, 시계열 분석·머신러닝 기반 예측 모델의 비교와 적용 전략을 제시하였다. 재생에너지·에너지 자립·연계형 운영 분야에는 Lee, Jung과 Choi (2020), Choi와 Kim (2025), Park, Choi, Jian, Han과 Rho (2022), Choi, Kim과 Won (2022), Lee, Kwag, Ha와 Kim (2025) 연구가 해당된다.
3.3. 제로샷 방식의 문헌분류 성능 평가
LLM이 도출한 7개 카테고리의 타당성을 확인하기 위해 연구자 4인은 각자 동일한 기준을 적용하여 분류 적절성을 검토하였다. 연구자들은 방법론에서 설정한 세 가지 판단 기준에 따라 각 논문이 해당 카테고리에 적절하게 분류되었는지를 독립적으로 평가하였으며, 평가는 “O/X” 방식으로 이루어졌다. 이러한 절차를 통해 LLM이 수행한 자동 분류 결과에 대한 인간 연구자 각각의 일치도는 Table 3에 제시되어 있다.
Table 3
Researcher Evaluation of ChatGPT-5.1 Zero-Shot Classification Results
*Paper numbers are consistent with Table 1.
연구자 A는 16건의 적합(O)과 8건의 부적합(X)을 기록하여 66.67%, 연구자 B는 18건의 적합과 6건의 부적합으로 75.00%, 연구자 C는 21건의 적합과 3건의 부적합으로 87.50%, 연구자 D는 20건의 적합과 4건의 부적합으로 83.33%의 일치도를 보였다. 최종 합의율은 75%로 산정되었다. 제로샷 방식에 의한 문헌 분류 성능 평가 결과 LLM 분류와 연구자 평가는 상당 수준의 일치도를 보였다. 특히 연구자 C와 D는 각각 87.50%, 83.33%로 높은 일치도를 나타냈다. 반면, 연구자 A는 상대적으로 낮은 66.67%의 일치도를 보였는데, 이는 LLM 분류와의 해석 기준 차이가 다소 존재했음을 의미한다. 전체적으로 볼 때, 연구자 네 명 모두 60~80% 이상의 일치도를 보임으로써 LLM의 초기 분류가 일정 수준 이상의 타당성을 확보했음을 알 수 있다.
3.4. 퓨샷 프롬프팅에 따른 연구 문헌 분류 결과
여기에서는 연구자 4인이 동일한 문헌을 대상으로 연구 목적, 연구 대상, 방법론이라는 세 가지 기준에 따라 분류 카테고리를 우선적으로 설정하였다. 설정한 카테고리는 다음과 같다.
① 설비·시스템 운영 및 효율 최적화
② 에너지 예측 및 분석
③ BEMS 관련 제어 알고리즘 연구
④ BEMS 관련 정책·표준화 방향 분석
⑤ BEMS 실증 기반 운영·적용성 평가
이후, 이렇게 설정된 카테고리를 LLM에게 퓨샷 방식으로 분류하게 하였다. 연구자가 정의한 연구문헌 분류 카테고리를 기반으로 한 퓨샷 프롬프팅에 의해 분류된 연구 논문 목록은 Table 4에 제시되어 있다.
Table 4
Few-Shot Classification Results Generated by ChatGPT-5.1 Based on the Researcher-Defined Classification Scheme
*Paper numbers are consistent with those presented in Table 1.
먼저 설비·시스템 운영 및 효율 최적화 분야에는 Kim 등(2020) 외 3개 문헌, 에너지 예측 및 분석 분야에는 Quan 등(2021) 외 6개 문헌이 해당하며 결측 보정·수요예측·태양광 발전량 예측 등 다양한 모델링 접근을 다루었다. BEMS 관련 제어 알고리즘 연구 분야에는 Bae과 Song (2024) 외 5개 문헌이 포함되며, 자동화된 제어·스마트빌딩·EMS 운영 개선을 중심 내용으로 한다. BEMS 관련 정책·표준화 방향 분석에는 Choi(2025) 외 3개 문헌이 포함되며, 제도·표준·규제 개선을 중심으로 BEMS 확산 기반을 검토하였다. 또한 BEMS 실증 기반 운영·적용성 평가 분야에는 Lee 등(2025) 외 2개 문헌이 포함되어 실제 건물 적용성, 경제성, 운영 특성을 검토하였다.
3.5. 퓨샷 방식의 문헌분류 성능 평가
연구자가 사전 설정한 문헌 분류 카테고리를 활용한 퓨샷 방식의 문헌 분류 성능 평가에서도 앞서 설명한 절차와 동일 방식으로 진행되었으며, 그 결과는 Table 5와 같다.
Table 5
Researcher Evaluation of ChatGPT-5.1 Few-Shot Classification Results Based on a Researcher-Defined Classification Scheme
*Paper numbers are consistent with Table 1.
연구자 A는 20건의 적합(O)과 4건의 부적합(X)을 기록하여 83.33%, 연구자 B는 23건의 적합과 1건의 부적합으로 95.83%, 연구자 C는 21건의 적합과 3건의 부적합으로 87.50%, 연구자 D는 22건의 적합과 2건의 부적합으로 91.67%의 일치도를 보였다. 최종 합의율은 95.83%로 산정되었다.
연구자들이 문헌 분류 카테고리를 제안한 경우, 제로샷 분류보다 더 높은 수준의 일치도와 최종 합의율을 보였으며, 특히 제로샷에서 낮은 일치율을 보였던 연구자 A는 83.33%의 향상된 일치율을 보였다. 다른 연구자들도 각각 95.83%, 87.5%, 91.67%로 제로샷 결과 이상의 일치율을 보였고, 네 명의 일치율은 80~90%에서 형성되었다.
이러한 결과는 인간 평가자의 합의에 의한 카테고리의 설정이 LLM 모델인 ChatGPT-5.1 이 설정한 카테고리 보다 더 문헌 분류에 적합할 수 있음을 의미한다. 단, 이는 제3자 평가를 수행하지 않고, 연구자가 설정한 기준에 따라 다시 연구자가 평가한 것으로 연구자의 내재적인 기준이 작용했을 수 있다는 한계가 존재한다.
그러나, 이는 사용자가 설정한 분류기준을 적용할 때, LLM이 자동으로 생성한 분류기준 보다 더 연구자에게 적합한 결과가 나온 것을 의미한다. 따라서, LLM을 이용한 연구 문헌 분류시, LLM as a Judge를 그대로 적용하는 것보다, 사용자의 적절한 조율과 개입을 통해 LLM의 평가 과정을 보완하는 것이 LLM 사용자에게 보다 적합한 결과를 도출하는 데 효과적일 것으로 판단된다.
3.6. Fleiss’ Kappa와 Gwet’s AC1 산출결과
먼저 제로샷 단계에서의 연구자 A~D의 일치율은 각각 66.67%, 75.00%, 87.50%, 83.33%로 평균 75% 수준을 보였다. 이 때 연구자들 간의 Fleiss’ kappa 는 k = 0.492로 나타났다. 이는 Fleiss’ kappa 평가 기준에 의하면 ‘보통 수준의 합의’에 해당한다. 이는 제로샷 기반 분류가 전반적으로 타당한 구조를 갖지만, 일부 논문에서는 분류 결과의 상이함이 존재했음을 의미한다.
이후, 연구자들이 작성한 문헌 분류 카테고리를 적용하여 LLM에 퓨샷으로 제공한 결과 LLM의 분류 적합성은 크게 향상되었다. 연구자 A~D의 일치율은 각각 83.33%, 95.83%, 87.50%, 91.67%로 나타났다. 이 때, Fleiss’ kappa는 k = 0.33으로, 제로샷 단계의 k = 0.492에 비해 오히려 감소하였다.
이러한 현상은 연구자 일치율이 크게 높아졌음에도 Fleiss’ kappa가 낮아지는 kappa 역설(Kappa Paradox)에 해당한다고 판단된다. 이는 연구자들이 내린 판단의 범주가 한쪽으로 치우칠 경우 우연에 의한 일치 수준이 높았다고 평가하는 Fleiss’ kappa의 구조적 한계에 기인한다. 즉, 퓨샷 단계에서 실제 분류 일치도는 증가하였음에도 대부분의 문헌이 ”적합(O)“에 집중됨으로 인해 최종적인 Fleiss’ kappa가 낮게 산출된 것으로 판단되었다.
이에 따라, Gwet’s AC1 지표를 활용하여 신뢰도 평가를 추가적으로 실시하였다. Gwet’s AC1 토대로 재계산한 결과 제로샷 분류에 대한 AC1 지표는 AC1=0.73, 퓨샷 분류에 대한 AC1 지표는 AC1=0.84로 나타났다. 대부분의 문헌이 ‘적합(O)’ 범주로 판단되는 퓨샷 분류가 제로샷 분류 대비 명확히 상승하였으며, 이는 분류 정확도와 연구자 판단 간 정합성이 실질적으로 개선되었음을 의미한다. 이러한 결과는 퓨샷 방식이 단순히 특정 범주로의 응답 집중을 유도한 것이 아니라, 연구자들이 합의한 분류 기준을 LLM이 보다 일관되게 적용함으로써 연구문헌 분류 과정에서의 신뢰성과 일치도를 동시에 향상시켰음을 시사한다.
4. 논 의
4.1. 연구자 간의 연구문헌 분류 적합성 평가 차이 원인
본 연구에서 LLM을 활용하여 분류된 논문 분류 카테고리에 대해 네 명의 연구자가 개별 논문에 대한 평가 적합성을 판단하는 과정에서 연구자 간 판단 일치도에 차이가 발생하였다. 이러한 차이는 주로 논문의 요약을 기반으로 적합성을 평가할 때, 사전에 정의된 평가 기준인 연구 목적, 연구 대상, 연구 방법론 중 각 연구자가 상대적으로 어떤 요소에 우선순위를 두고 집중했는지에 기인한 것으로 추정된다. 결과적으로 이러한 평가 초점의 차이가 동일한 논문에 대한 연구자 간의 상이한 적합성 판단을 초래한 핵심적인 원인으로 작용했을 가능성이 높다.
이러한 상황은 LLM 기반의 평가에서 인간 평가자의 개입 과정에서 적절한 평가 기준을 수립하고 활용하는 것이 최종 결과의 품질과 신뢰도를 확보하는 데 필수적일 수 있음을 시사한다. 따라서 향후 유사한 연구 수행 시 평가 요소별 가중치 또는 구체적인 판단 예시를 포함하는 표준화된 검토 프로토콜을 도입하여 연구자 간의 주관적 해석의 여지를 최소화하는 방안이 필요할 것으로 판단된다.
4.2. LLM as a judge에 의한 분류의 방법론적 시사점
본 연구는 LLM 기반 문헌 분류의 신뢰도와 타당성을 검증하기 위해 제로샷 방식과 퓨샷 방식을 단계적으로 비교하고, 그에 따른 방법론적 시사점을 확인할 수 있었다. 분석 결과, 연구자가 명확한 분류 기준과 예시를 제시한 퓨샷 방식은 제로샷 방식 대비 연구자 판단과의 정합성을 크게 향상시킨 것으로 나타났다. 제로샷 단계에서 연구자 최종 합의율은 75% 수준이었으나, 퓨샷 적용 이후에는 95.83%로 크게 상승하였으며, 이는 LLM이 사전에 정의된 분류 규칙을 적용할 경우 BEMS와 같이 주제와 방법론이 복합적인 문헌 분류 과제에서도 인간 전문가 판단에 근접한 분류 성능을 확보할 수 있음을 실증적으로 보여주는 것으로 해석될 수 있다. 또한 Gwet’s AC1 지표를 활용한 신뢰도 분석 결과에서도 제로샷 분류는 0.73, 퓨샷 분류는 0.84로 나타나, 퓨샷 방식에서 분류 신뢰도가 보다 안정적으로 향상되었음을 확인하였다. 이는 퓨샷 방식이 단순한 응답 집중 효과가 아니라, 문헌 자료 분류에 있어 명확한 기준 제공을 통해 LLM의 문헌 분류 성능을 개선했음을 의미한다. 이러한 결과를 종합하면, LLM 기반 연구동향 분석에서 분류 성능을 극대화하기 위해서는 명시적인 분류 기준과 예시를 활용한 퓨샷 방식의 활용이 효과적인 대안이 될 수 있음을 확인할 수 있다.
4.3. Fleiss’ kappa 활용의 한계
본 연구에서는 퓨샷 단계에서 연구자 일치도가 크게 향상되었음에도 불구하고 Fleiss’ kappa 값이 0.33으로 도출되는 현상이 관찰되었다. 이는 문헌 자료의 분류 결과가 특정 범주, 특히 ‘적합(O)’ 판단으로 집중되는 고일치·고편중 환경에서 Fleiss’ kappa가 실제 합의 수준을 과소평가하는 kappa 역설(Kappa Paradox)에 해당하는 결과로 해석된다. 따라서 kappa 계수의 단일 수치만을 근거로 LLM as a judge를 활용한 문헌 분류의 성능을 판단하기보다는, 연구자 일치도 평가 결과 및 적절한 보조지표를 활용한 종합적 해석을 활용하는 것이 바람직할 것으로 판단된다. 본 연구에서는 범주 편중 상황에서도 보다 안정적인 신뢰도 평가가 가능한 Gwet’s AC1 지표를 함께 활용하였으며, 그 결과 퓨샷 분류의 신뢰도가 제로샷 대비 명확히 향상되었음을 확인하였다. 향후 연구에서는 범주 편중의 영향을 최소화하기 위한 평가 체계의 개선과 함께, 다양한 신뢰도 지표를 결합한 다각적 검증 체계의 검토가 필요할 것으로 판단된다.
4.4. 평가자 선정과 인원 수의 한계
본 연구의 한계점은 LLM의 문헌 분류 결과를 검증하기 위해 참여한 인간 평가자는 건축공학 전공 학부생 수준의 평가자 4인으로 제한적이었다. 전문가를 이용한 합의는 다수의 인력을 확보하기 어렵다는 한계가 존재하나 훈련받은 학부생 수준의 평가자는 모집과 활용에 용이한 장점이 있다. 이에 따라, 훈련된 전공자 수준의 평가와 LLM 평가의 비교 분석은 향후 LLM의 활용 범위를 넓혀 줄 수 있다는 장점을 가진다. 이에 따라 본 연구에서는 LLM as a judge로서의 성능 평가 시 일정한 수준으로 훈련된 전공자 집단에 의해 안정적인 평가 가능성도 함께 검토되었다. 한편, Fleiss’ kappa 및 Gwet의 AC1은 3인 이상의 다수 평가자 구조에서 적용 가능한 통계량으로, 평가자 수가 적다 하더라도, 통계적 활용성이 제한되지는 않는다. 이에 따라 본 연구는 평가 기준의 일관성을 통제할 수 있는 평가자 규모로 4인을 채택하였으며, 향후 연구에서는 보다 엄격한 기준과 사전 교육을 통해 통제력을 유지한 표본 수를 확대해 나갈 예정이다.
5. 결 론
본 연구는 대규모 언어 모델을 활용한 LLM as a Judge 기법을 기반으로 국내 BEMS 연구 문헌 자동 분류의 적용 타당성과 신뢰성을 검증하는 것을 목표로 한다. 이를 위해 사전 기준 없이 분류를 수행한 제로샷 방식과, 연구자가 명확한 분류 기준을 제시한 퓨샷 방식을 비교하였다. 그 결과는 다음과 같이 정리될 수 있다.
첫째, LLM을 활용한 문헌 자료 분류 결과와 연구자 판단 간의 일치도 측면에서 제로샷 방식도 일정 수준 이상의 일치도가 확인되었으나, 연구자가 사전에 정의한 분류 기준을 제공한 퓨샷 방식에서는 최종 합의율이 95.83%로 크게 향상되었다. 이를 통해 복합적인 연구 주제와 방법론을 포함하는 BEMS 분야 문헌 분류에서, 명확한 기준과 예시를 제공하는 퓨샷 방식이 보다 적합한 방식임을 확인할 수 있었다.
둘째, 네 명의 연구자가 수행한 분류 적합성 판단 결과를 바탕으로 Fleiss’ kappa 및 Gwet’s AC1를 산정하여 연구자 간의 평가 일치도를 분석하였다. 그 결과 퓨샷 방식에서 연구자 간 관찰된 일치도가 크게 향상되었음에도 Fleiss’ kappa 값이 오히려 감소하는 현상이 나타났다. 이는 kappa 역설(Kappa Paradox)에 해당하는 것으로 해석되며, Gwet’s AC1 지표를 보조적으로 활용한 결과 퓨샷을 이용한 문헌 분류의 신뢰도가 제로샷 대비 명확히 향상되었음을 확인할 수 있었다.
셋째, 최종적으로 LLM as a judge를 활용한 문헌 분류 방법은 복잡하게 분화된 BEMS 연구 문헌을 효과적으로 분류할 수 있음을 확인할 수 있었다. 특히 명확한 분류 기준과 예시를 제공하는 퓨샷 방식이 보다 효과적인 결과를 보여, 현재의 LLM 수준에서는 LLM as a Judge를 활용한 완전 자동화 문헌 분류보다는 사용자의 적절한 개입이 필수적임을 시사한다.
본 연구는 복잡한 건축공학 분야에서 LLM을 활용한 데이터 분류와 처리를 위한 기초적 근거를 활용했다는 의미를 가진다. 단, 본 연구는 퓨샷 기법 평가 과정에서 연구자가 설정한 분류 기준을 동일한 연구자가 다시 평가하는 구조를 취하였으므로, 제3자에 의한 독립적 검증이 수행되지 않았다는 한계가 있어 추후 연구에서 보완할 필요성이 있을 것으로 판단된다.
