

1. 서 론
2. 선행연구 조사
2.1. 태양광 예측 모델의 연구 동향
2.2. 태양광 예측 모델의 불확실성에 대한 연구 동향
3. 머신러닝 모델 정규화(Regularization) 기술 관련 이론적 고찰
3.1. Bayesian
3.2. Ensemble
3.3. Dropout
3.4. Early Stopping
3.5. Lasso & Ridge Regression
4. 연구방법
4.1. 수집한 데이터의 종류 및 변수 선정
4.2. 모델 및 알고리즘 개요
4.3. 모델 평가 지표
4.4. Case 선정
5. 결과 및 분석
5.1. Case별 예측 결과 비교
5.2. Case별 오차 값 분포 분석
5.3. 고습 조건에서의 예측 결과 비교
5.4. 시간대별 과소 및 과대 확신 비교
6. 결 론
1. 서 론
전 세계적으로 지속 가능한 에너지 개발과 기후 변화 저감을 위한 해결책을 모색하는 가운데, Decarbonisation이 중요한 문제로 대두되고 있다. 이러한 배경에는 증가하는 에너지 수요를 친환경적이며 경제적으로 충족하는 것에 대한 필요성으로 시작되었다. 그에 따라 재생에너지의 개발과 보급은 미래의 핵심 에너지원으로 자리매김할 가능성을 보인다(Boza & Evgeniou, 2021). 대한민국의 경우 신재생 에너지의 비중은 꾸준히 증가하여 2022년 기준 전체 에너지 중 신재생 에너지 발전량 비중은 8.3%이며, 이 중 태양광이 15.3%로 가장 높은 것으로 나타났다(Choi & Ahn, 2023). 그러나 태양광 에너지의 경우 외부 환경의 변화에 따라 출력이 일정하지 않은 간헐성 및 예측 불확실성을 내재하고 있다(Park, Kim, Lim, & Kim, 2017). 이러한 문제점을 해결하기 위하여 산업통상자원부에서 2020년 9월 재생에너지 발전량 예측 제도를 도입하였으며, 이를 통해 재생에너지 간헐성으로 인해 발생하는 비용과 전력 계통을 보다 효율적으로 운영할 수 있을 것으로 기대하였다(Ministry of Trade, Industry and Energy, 2020). 그러나 다양한 분야에 인공지능의 급속한 도입과 혁신의 창출 속에서 예상치 못한 사회적 이슈들 역시 함께 나타나고 있다. 이러한 부작용에 대응하기 위해, 대한민국 정부는" 사람이 중심이 되는 인공지능을 위한 신뢰할 수 있는 인공지능 실현 전략"을 2021년에 발표하여 인공지능의 신뢰 확보를 촉진하고 있다(Ministry of Science and ICT, 2021).
이처럼 인공지능의 신뢰성에 대한 문제는 전 세계적으로 논의되고 있다. 세계 주요 기관에서는 주장하는 인공지능 신뢰성 개념은 아래 Table 1과 같으며, 대부분의 주요 기관에서는 안전과 책임을 강조하고 있다. 대한민국의 경우 인공지능의 5대 주요 구성요소로서 안전, 투명성, 설명 가능성, 견고성, 공정을 언급하였다(Ministry of Science and ICT, 2021).
Table 1.
Reliability of Artificial Intelligence (EC, 2019; ISO, 2020; NIST, 2019; OECD, 2019)
모델의 신뢰성 및 불확실성에 대한 이해와 그 관리는 더욱 중요해지고 있다. 불확실성 정량화(Uncertainty Quantification, UQ)는 모델의 신뢰성을 높이고 결과 해석 가능성을 제공함으로써, 인공지능 시스템의 안정성을 보장하는 데 필수적이다(Sin & Hwang, 2022).
따라서 본 연구에서는 머신러닝을 활용한 태양광 발전량 예측에서 사용되는 정규화 기술을 바탕으로 불확실성 정량화(Uncertainty Quantification)를 통한 태양광 발전 성능 예측 모델의 일반화 가능성을 탐구하고 예측 성능을 비교하고 모델의 신뢰성을 높이는 방안을 제시하고자 한다.
2. 선행연구 조사
본 연구에서는 Machine Learning을 활용한 태양광 예측에 대한 최근 연구들을 조사하였다. 2019년부터 2023년까지 발표된 연구를 대상으로 하였으며, 이를 위해 ScienceDirect 데이터베이스를 활용하였다. 분석한 연구들의 신뢰성을 확보하기 위해 Impact Factor 5.0 이상의 학술지 중 다섯 곳을 선정하였다. 선정된 학술지는 Applied Energy, Energy, Solar Energy, Renewable Energy, Sustainable Cities and Society이다. 또한 검색 시 Title, abstract or author-specified keywords에 해당 용어가 포함된 경우만을 선정하여 분석하였다.
2.1. 태양광 예측 모델의 연구 동향
최근 5년간 ‘Machine Learning’과 ‘PV’라는 용어가 포함된 논문을 분석한 결과, 총 111편의 논문이 발표되었다. 태양광 예측과 관련된 논문은 2019년 이후 꾸준히 증가하고 있다. 이러한 연구들은 XGBoost, Random Forest, CNN 등의 다양한 기법을 사용하여 예측 모델을 개발하였으며, 개발된 모델의 성능은 CV(RMSE), NMBE, R2 등의 평가 지표를 활용하여 평가되었다. 해당 논문들의 연구 주제를 분석한 결과는 Table 2에 제시되어 있으며, ‘Prediction of PV Generation’이 가장 많은 연구가 수행된 주제로 확인되었다. 또한 ‘Fault Detection’과 ‘Optimization’도 비교적 활발하게 연구되고 있는 주제로 나타났다. 이를 통해 태양광 발전 예측 분야의 연구 동향을 명확하게 파악할 수 있다.
Table 2.
Number of Machine Learning, PV Related Publications
2.2. 태양광 예측 모델의 불확실성에 대한 연구 동향
최근 5년간 ‘Machine Learning’, ‘PV’, 및 ‘Uncertainty’라는 용어가 포함된 논문을 분석한 결과, 총 17편의 논문이 발표되었다. 태양광 예측 모델의 불확실성과 관련된 논문은 2019년 이후 꾸준히 증가하고 있다. 이 논문들을 분석한 결과, CNN, RNN(LSTM), Ensemble 기법 등 다양한 방법을 통해 예측 모델의 불확실성을 해결하고자 하는 시도가 이루어지고 있음을 확인할 수 있었다. 해당 논문들의 연구 주제는 Table 3에 제시되어 있으며, ‘Prediction of PV Generation’이 가장 활발하게 연구된 주제로 나타났다. 또한 ‘Demand Response’와 ‘Optimization of PV Systems’도 비교적 활발하게 연구되고 있는 주제로 확인되었다. 이러한 분석을 통해 태양광 발전 예측과 불확실성과 관련된 연구 분야의 동향과 변화 양상을 명확히 이해할 수 있다.
3. 머신러닝 모델 정규화(Regularization) 기술 관련 이론적 고찰
정규화는 학습 알고리즘을 변화시켜 훈련 오류를 최소화하지 않으면서도 일반화 오류를 감소시키는 방법으로 Goodfellow에 의해 정의되었다. 정규화 기법에는 주로 두 가지 접근 방식이 존재한다. 첫 번째는 매개변수 값에 제한을 두어 모델의 복잡성을 낮추는 방법이고, 두 번째는 목적 함수에 페널티 항을 추가하여 매개변수에 소프트 제약을 가하는 방법이다. 대부분의 정규화 기법은 Estimator에 기반을 두고 있으며, 이는 약간의 편향을 허용함으로써 모델의 분산을 줄여 성능을 향상 시키려는 방식이다. 대표적인 기법으로는Bayesian 기법, Dropout, 그리고 Early Stopping 등이 있으며, 이러한 방법들은 모델의 일반화 성능 강화에 기여하고 있다(Goodfellow, Bengio, & Courville, 2016).
3.1. Bayesian
Bayesian 신경망은 매개변수를 확률 분포로 모델링하여, 모델의 불확실성을 다루고자 하는 접근 방식이다. 이 방법은 매개변수를 적분하여 전체 예측 분포를 결정함으로써 불확실성을 측정한다. 그러나, 현대 신경망은 수백만 개의 매개변수를 가지기 때문에 사후 확률 분포의 직접 계산은 매우 복잡하다. 이를 효율적으로 처리하기 위해 Variational Inference 및 Markov Chain Monte Carlo와 같은 기법들이 활용되고 있다(Kendall & Gal, 2017).
3.2. Ensemble
Ensemble 기법은 여러 개의 모델을 독립적으로 훈련하여 각각의 예측을 생성한 다음, 이 예측들을 통합하여 최종 결과를 도출하는 방법이다. 이 방법은 다양한 기본 모델들이 제공하는 상보적 특성을 활용하여 전체적인 성능을 향상시킨다. 기본 모델들의 출력 값의 분산을 인식적 불확실성으로 간주할 수 있으며, 이를 통해 학습 과정에서 예측의 신뢰성을 평가할 수 있지만, 결과의 해석이 더욱 복잡해질 수 있다(Jain, Liu, Mueller, & Gifford, 2020). Ashukha, Lyzhov, Molchanov과 Vetrov (2020)은 앙상블 모델의 성능을 평가하기 위한 방법으로 Deep Ensemble Equivalent(DEE) 점수를 제안하였으며, 이 점수를 통해 다수의 기본 모델 중 앙상블 모델과 유사한 성능을 내는 모델은 극소수에 불과하다는 것을 밝혔다. 또한, 테스트 데이터 증강(Test Time Augmentation)을 통해 이러한 성능을 더욱 개선할 수 있다고 주장하였다.
3.3. Dropout
Dropout 기법은 학습 과정에서 임의로 뉴런을 비활성화하여, 네트워크가 특정 뉴런이나 경로에 의존하는 것을 방지하는 방법이다. 이 기법은 뉴런 간의 공동 적응을 줄여 모델의 일반화 성능을 높이는 데 기여하며, 다양한 모델을 학습하는 것과 유사한 효과를 발휘함으로써 Ensemble 기법과 비슷한 이점을 제공할 수 있다. 또한, Dropout의 비율을 최적화하려는 연구가 지속적으로 이루어지고 있으며, 이를 통해 보다 효과적인 모델 불확실성 추론법을 개발하여 실제 적용과 계산 효율성 면에서 긍정적인 결과를 얻고 있다(Hinton, Srivastava, Krizhevsky, Sutskever, & Salakhutdinov, 2012; Abdar et al., 2021).
3.4. Early Stopping
신경망 학습에서 과적합을 방지하고 모델의 일반화 성능을 개선하기 위해 중요한 방법 중 하나는 Early Stopping이다. 학습이 진행되면서 모델이 학습 데이터셋에 지나치게 특화되는 경향이 생길 수 있으며, 이로 인해 검증 데이터셋(Validation set)에서의 성능이 하락할 수 있다. 학습 초기에는 예측 모델의 성능이 향상될 것으로 예상되지만, 실질적으로 특정 지점 이후에는 성능이 감소할 수 있는 문제가 발생하기 때문에, 이러한 문제를 피하기 위해 학습을 중단하는 시점을 설계한다. 그러나 이 기법을 적용할 때 데이터의 크기와 특성, 모델 구조 등을 고려하여 신중하게 설정하는 것이 중요하다고 강조했다. Early Stopping을 올바르게 설정하지 않으면 성능이 저하될 수 있으며, 손실(loss)이나 오류(error)를 기준으로 삼는 것이 바람직하다고 주장했다. 이 기법은 모델의 일반화와 학습 시간 단축에 이점이 있지만, 더 많은 학습을 수행했을 때 더 나은 예측 결과를 얻을 수 있는 가능성을 제한할 수도 있다는 한계점이 존재한다(Prechelt, 2002).
3.5. Lasso & Ridge Regression
Lasso(L1)와 Ridge Regression(L2) 기법은 회귀 분석에서 모델의 복잡성을 줄이고 과적합을 방지하기 위해 널리 사용된다. L1 규제는 회귀 계수의 절대 값의 합에 제약을 가하여, 일부 계수를 정확히 0으로 만들어 변수 선택과 모델 단순화를 진행한다. 이는 고차원 데이터에서 유용하고 모델의 해석 용이성을 높여주는 장점이 있지만, 상관관계가 높은 변수 중 하나만 선택하고 나머지는 제거하는 경향이 있어 중요한 변수가 빠질 경우 예측 성능 저하의 위험이 있다(Tibshirani, 1996). 반면, L2 규제는 회귀 계수의 제곱합에 제약을 가해 모든 계수의 크기를 줄이면서 다중공선성을 해결하고 과적합을 방지한다. 이는 모든 변수를 모델에 남겨둠으로써 불안정성을 줄이지만, 해석이 어렵고 많은 변수를 다룰 때는 과적합 문제 해결에 한계가 있을 수 있다(Hoerl & Kennard, 1970).
Luo, Chang과 Ban (2016)은 L1 및L2 규제를 통한 모델 적용이 예측 성능에 미치는 영향을 평가하기 위해 여러 데이터셋에 실험을 실시하였다. 그 결과, L1 및 L2를 적용한 모델은 기본 모델인 ELM과 비교하여 모든 데이터셋에서 예측 성능이 향상됨을 확인하였지만, 학습 및 예측 시간의 증가로 인해 모델 구조의 복잡성도 역시 증가한다고 주장하였다.
4. 연구방법
4.1. 수집한 데이터의 종류 및 변수 선정
수집된 태양광 발전 데이터는 진천 에너지 타운의 태양광 발전 시스템을 통해 측정된 데이터로 2019년 1월 2일부터 2019년 7월 8일까지 총 4,152 시간으로 구성 되어져 있다. 태양광 발전 시스템은 총 848.kW이며, 해당 시스템은 5구역으로 나뉘어 옥상 및 주차장에 설치되어 있다(Kim, Heo, Kim, & Lee, 2021). 입력 및 출력변수 선정의 경우 Pearson Correlation Coefficient(PCC)를 통하여 진행하였다. 상관 분류하는 방법은 다양하지만, 이러한 기준은 일관성이 없어 적용 시 신중할 필요가 있다. 따라서 본 연구에서는 선행연구를 기반으로 하여, 유의미한 관계를 나타내는 상관관계 값을 0.3으로 분류하였다(Cohen, 2013; Schober, Boer, & Schwarte, 2018). 이에 따라 선정된 입력 및 출력 변수는 Table 4와 같다.
Table 4.
Correlation Between Input Variable and Output Variable
| Input Variable | Output Variable | ||
| Temperature (°C) | 0.3 | PV Generation | 1 |
| Humidity (%) | ‒0.39 | ||
| Daylight (hr) | 0.77 | ||
| Insolation (MJ/m2) | 0.91 | ||
| Ground Temperature (°C) | 0.58 | ||
| PV Generation (t-1) | 0.93 | ||
4.2. 모델 및 알고리즘 개요
본 연구에서는 모델의 예측 성능을 비교하기 위해 ANN, LSTM, XGBoost를 사용했다.
ANN(Artificial Neural Network)의 경우 생물학적 신경망을 모델링한 수학적 구조로, 입력층, 은닉층, 출력층으로 구성된다. 각 층의 노드들은 가중치와 활성화 함수를 통해 신호를 전달하며 복잡한 패턴을 학습할 수 있다. 하지만, ANN은 Gradient Vanishing 문제와 과적합 현상에 취약점이 있어 예측 성능이 저하될 수 있다(Park, Hong, Yeon, Seo, & Lee, 2023).
LSTM(Long Short-Term Memory)의 경우 순차 데이터 처리에 특화된 RNN의 개선된 형태인LSTM은 장기 의존성 문제를 게이트 구조로 해결한다. 네 가지 계층(포겟 게이트, 입력 게이트, 셀 상태, 출력 게이트)으로 구성되어 있으며, 시간의 흐름에 따라 정보의 저장과 제거를 효과적으로 처리한다. 이로 인해 LSTM은 시간 의존적인 데이터를 모델링하는 데 탁월하다(Olah, 2015).
XGBoost의 경우 구조적 데이터의 예측 문제에 많이 사용되는 고성능 머신러닝 알고리즘이다. 결정 트리를 기반으로 한 부스팅 기법을 통해 여러 약한 학습기를 결합하여 강력한 예측 모델을 구축한다. XGBoost는 경량화된 Gradient Boosting 기술을 활용하여 빠르고 효율적으로 학습하면서도 높은 성능을 발휘한다(Chen & Guestrin, 2016).
4.3. 모델 평가 지표
본 연구에서는 모델의 예측 성능을 평가하기 위해 CV (RMSE)을 활용하였다. CV(RMSE)는 모델이 얼마나 정확한 예측을 하는지를 보여주는 지표로, 평가가 직관적이며 명확한 결과를 제공한다. 이 평가 방법은 ASHRAE Guideline 14에서 권장된 방식으로, 신뢰할 수 있는 기준을 제시한다. 특히 1시간 간격으로 수집된 데이터를 평가할 때, CV(RMSE) 값이 30% 이하일 경우 예측 성능이 양호하다고 간주되며, 이는 아래 수식 (1), (2)에 따라 계산된다(A.S.H.R.A.E., 2014).
4.4. Case 선정
본 연구에서는 머신러닝의 정규화 기법이 모델의 성능에 미치는 영향을 분석하기 위해 4가지 모델을 선정하였다. 각 Case는 동일한 데이터셋과 학습 조건을 기반으로 하였으며, 학습 조건은 다음과 같다: Hidden layer는 2, Hidden node는 10~15, Epoch = 50, Data set(Train 70%, Test 30%), Early Stopping = 10으로 설정하였다.
Case 1 : ANN
Case 2 : LSTM
Case 3 : ANN + XGBoost
Case 4 : LSTM + XGBoost
이를 통해 다양한 모델의 예측 성능을 비교하고 정규화 기법의 일반화 성능에 대해 알아보고 각 Case의 오차 분포를 분석하여 어떤 모델이 가장 우수하고 일관된 성능을 나타내는지를 파악하고자 한다.
5. 결과 및 분석
5.1. Case별 예측 결과 비교
본 연구에서는 선정된 네 가지 모델(Case 1~4)의 예측 정확도를 ASHRAE Guideline 14의 CV(RMSE)를 기준으로 비교하였다. 분석 결과, LSTM을 기반으로 한 모델들(Case 2와 4)이 다른 모델들에 비해 상대적으로 우수한 예측 성능을 보여주었으며, 특히 Case 4 (LSTM + XGBoost)가 가장 뛰어난 결과를 나타냈고, 이는 Table 5, Figure 1과 같다. 이러한 결과는 LSTM의 시계열 데이터를 처리하는 능력과 XGBoost의 강력한 예측 능력이 결합 되면서 모델의 성능이 극대화된 것으로 보인다.
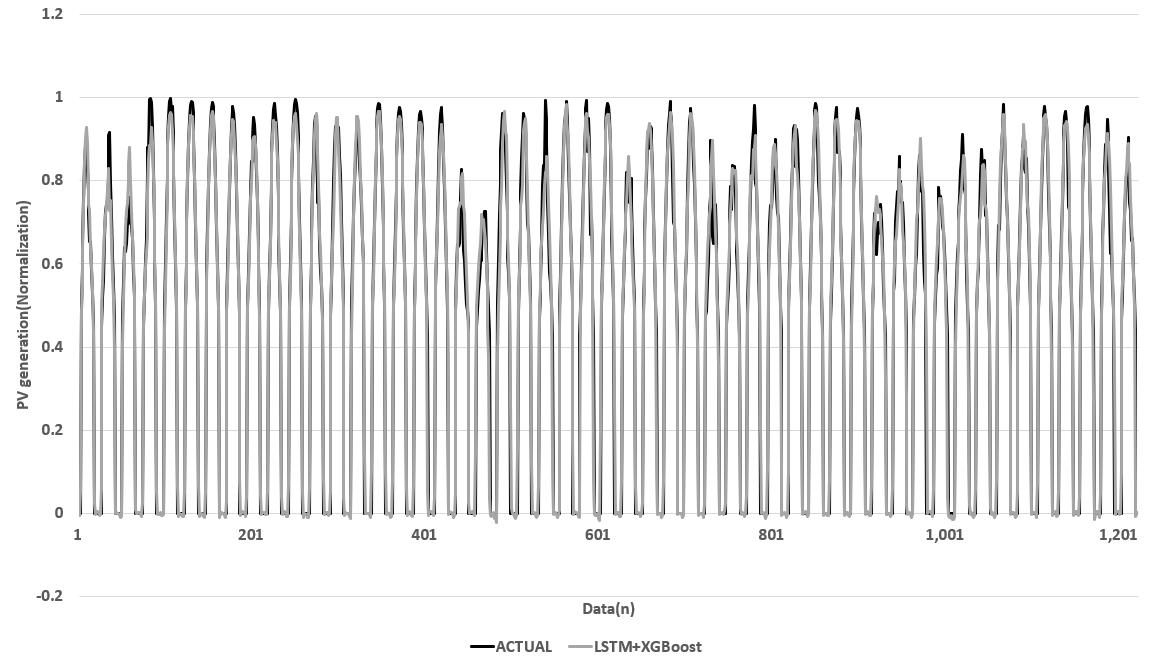
Table 5.
Predictive Performance by Case
| Case | CV (RMSE) (%) | Hidden Node 1 | Hidden Node 2 |
| 1 | 25.67 | 22 | 21 |
| 2 | 15.08 | 21 | 25 |
| 3 | 25 | 22 | 25 |
| 4 | 11.93 | 23 | 21 |
5.2. Case별 오차 값 분포 분석
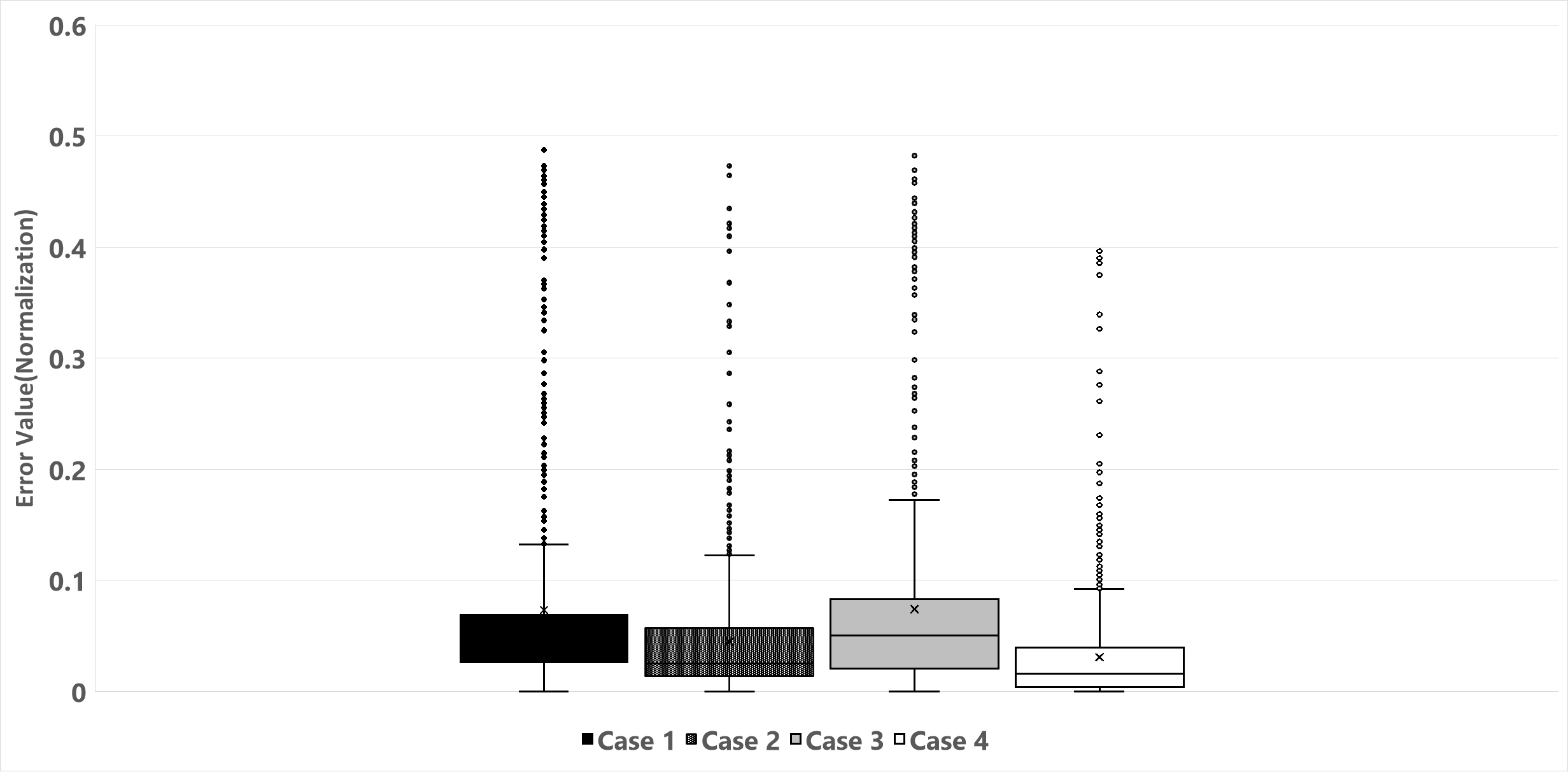
본 연구에서는 각 Case의 오차 분포를 분석하여, 어떤 모델이 가장 우수하고 일관된 성능을 나타내는지를 파악하고자 하였다. Table 6과 Figure 2에 나타난 바와 같이, 이를 위해 사분위수, 최대 및 최소 값을 평가하였다. 제2 사분위수는 오차값의 중앙값을 나타내며, Case 4에서 가장 낮은 값을 보였다. 이는 Case 4의 경우 다른 Case에 비해 예측 성능과 일관성이 뛰어날 가능성이 높다는 것을 의미한다. 또한, 사분위 범위 역시 Case 4가 가장 작아 예측값의 변동성이 낮고 일관성이 높음을 나타냈다. 최댓값과 최솟값의 범위를 통한 분석에서는 Case 4가 가장 낮은 극단적인 오차범위를 유지하여, 다양한 조건에서도 가장 우수한 성능을 발휘함을 알 수 있다.
Table 6.
Summary of Quartiles by Scenario
5.3. 고습 조건에서의 예측 결과 비교
본 연구에서는 고습 조건을 통해 모델의 예측 성능을 분석하였다. 이러한 환경은 예측의 불확실성을 증가시키고 시스템 성능에 직접적인 영향을 미치는 주요 요인이기 판단된다. 고습의 기준은 습도가90% 이상인 경우로 하였으며, 이는 비나 구름이 많은 시기로, 태양광 발전에 부정적인 영향을 미쳐 에너지 생산 변동성을 증가시킬 수 있다. 이러한 상황은 자료 수집 시 센서 오류를 증가시키고, 데이터 품질에도 부정적 영향을 미칠 가능성이 있다.
이러한 배경하에, 고습 조건에서의 예측 성능을 비교하였으며, 이는 Table 7과 같다. 모든 Case에서 예측 정확도가 저하되는 모습을 보였으나, LSTM 기반 모델들(Case 2와 4)은 상대적으로 안정적인 성능을 유지하였다. 이는 고습 조건이 예측의의 불확실성을 증가시킨 환경에서도 LSTM의 시간적 패턴 처리 능력과 XGBoost의 비선형 관계 인식 능력이 결합되어 상대적으로 뛰어난 예측 성능을 나타낸다.
Table 7.
Predictive Performance by Case in High Humidity
| Case | CV (RMSE) |
| 1 | 54.4 |
| 2 | 20.58 |
| 3 | 53.68 |
| 4 | 20.49 |
5.4. 시간대별 과소 및 과대 확신 비교
본 연구에서는 Case별 예측 값의 과소 및 과대 확신을 평가하였으며, 이는 Figure 3 및 Table 8과 같다. Case 1의 경우 주로 과대 확신 결과가 나타났는데 이는 ANN은 주로 비선형 데이터 패턴에 민감하게 반응하기 때문으로 보인다. 반면, LSTM을 사용한 Case 2는 초기에는 약간의 과소 평가를 나타내다가, 시간이 지남에 따라 과대 확신으로 전환되었다. 이는 LSTM의 특징인 장기적 의존성 특징으로 보이며, 태양광 생산량이 많은 시간대에서 대부분 과대 확신이 나타났다.

Table 8.
Under & Overconfidence Count by Case
| Case | Underconfidence | Overconfidence |
| 1 | 8 | 16 |
| 2 | 9 | 15 |
| 3 | 9 | 15 |
| 4 | 13 | 11 |
앙상블 기법을 사용한 Case 3의 경우 비교적 안정적인 예측 결과를 보였다. 이러한 결과는 예측의 일관성을 유지하게 하며, 실제 데이터와의 일치도를 높다는 것을 의미한다. 마지막으로 Case 4의 경우 대부분의 시간대에 걸쳐 실제 값에 유사한 예측 값을 나타냈다. 이는 LSTM의 패턴 인식 기능과 XGBoost의 피처 중요도 분석이 잘 결합되어 보다 정확한 예측을 가능한 것으로 보인다. 또한 Case 4를 제외한 모든 Case에서 과대 확신이 상대적으로 높게 나타났으나 오차 값 분포 분석에서도 나타난 바와 같이 앙상블 모델이 단일 모델보다 예측의 변동성을 적고, 실제 데이터와 유사한 그래프 형태가 나타났다.
주목할만한 점은, 사분위수에 기반한 분석이 보여주는 모델 성능 순위와 시간별 평균 오차 기반 분석의 순위가 차이를 보인다는 것이다. 사분위수 분석에서는 LSTM 기반인 Case 4와 Case 2가 뛰어난 성적을 보였으나, 시간별 평균 오차 분석에서는 Ensemble기반인 Case 4 다음으로 Case 3이 우수한 성능을 나타냈다. 이는 각 Case의 특정 시간대나 조건에서의 성능이 다를 수 있음을 시사한다.
특히, 사분위수는 데이터의 중앙 집중 경향과 변동성을 평가하며 고른 성능을 보이는 반면, 시간별 평균 오차는 몇몇 시간대의 성능이 전체적인 성능에 큰 영향을 줄 수 있다. 예를 들어, Case 3이 특정 시간대에서 작거나 큰 오차를 나타낼 때, 이 시간대의 성능이 전체 평균에 상당한 영향을 미친다는 것을 의미한다. 따라서, 서로 다른 평가 기준이 다른 성능 순위를 나타낼 수 있음에 주목할 필요가 있으며, 이는 최종 모델 선택 시 다양한 측면을 고려해야 함을 의미한다.
6. 결 론
본 연구에서는 기계 학습 기법과 불확실성 정량화(Quantification of Uncertainty, UQ)를 통해 태양광 발전량 예측 모델의 성능을 개선하고 신뢰성을 높이기 위한 다양한 접근을 탐구하였다. 다양한 모델들을 비교 분석한 결과, LSTM과 XGBoost를 결합한 모델(Case 4)이 다른 모델들에 비해 전반적으로 뛰어난 성능을 나타냈다. 이는 LSTM의 시계열 데이터 처리 능력과 XGBoost의 비선형 관계 인식 능력이 결합되어 예측의 정확성과 일관성을 극대화할 수 있었음을 시사한다.
특히, 고습 조건에서도 LSTM 기반 모델들이 다른 모델에 비해 안정적인 예측 성능을 유지함을 확인하였다. 이러한 결과는 예측 모델이 환경적 변화에 대해 유연함을 가지며 실용적 적용 가능성이 높다는 것을 의미한다.
또한, 사분위수 분석에서의 모델 성능과 시간별 평균 오차에서의 모델 성능 순위에는 차이가 발생하였다. 이는 신뢰성 높은 최종 모델 선별 시 다양한 분석에서의 접근이 필요함을 의미한다.
본 연구는 머신러닝의 정규화 기술을 통해 모델의 신뢰성을 한층 강화하고, 예측의 일관성과 정확성을 높일 수 있음을 확인하였다. 이는 재생에너지의 간헐성 문제 해결 및 안정적인 전력 공급체계 구축에 기여할 수 있을 것으로 판단된다.
그러나 이 연구는 몇 가지 한계를 가진다. 첫째, 데이터 수집 범위가 특정 지역으로 제한되어 있어, 다양한 환경과 상황에서의 일반화 가능성은 추가 연구가 필요하다. 둘째, 연구에서 사용된 알고리즘의 매개변수 최적화와 추가적인 변수 발굴을 통해 성능을 더 향상 시킬 여지가 있다. 추후 연구에서는 더 다양한 환경에서의 데이터 수집 및 분석, 그리고 최신 알고리즘 활용을 통한 성능 최적화를 통해 태양광 발전 예측 모델의 실효성을 높이는 방향으로 나아가야 할 것이다.
