

1. 서 론
2. 인공지능에서의 불확실성
3. 연구 방법
3.1. 수집한 데이터의 종류와 특성
3.2. Artificial Neural Networks
3.3. Pearson Correlation Coefficient 및 변수 선정
3.4. 데이터 유사성 평가 방법
3.5. 시나리오 선정
3.6. 예측 모델 개발 과정
3.7. 예측 모델 성능 평가
4. 예측 결과 및 시나리오 비교 분석
4.1. 정규화 방법에 따른 예측 결과 비교
4.2. 시나리오 비교
5. 결 론
Appendix A
Abbreviations
1. 서 론
온실가스 감축에 대한 국내외적 관심이 증가함에 따라 대한민국 정부 역시 2030년까지 재생에너지 발전 비중 20%을 목표로 한 ‘재생에너지 3020 정책’을 발표하였다(Jeon, Jo, & Cho, 2019). 한국에너지 공단 발표에 따르면 전체 재생에너지 중 태양광과 태양열의 비중은 매년 증가하고 있으며, 2022년 기준 약 42%를 차지하는 것으로 나타났다(Korea Energy Agency, 2022). 그러나 태양광 발전은 기존 발전원에 비해 간헐성이 크고 시간, 지역 및 계절에 따른 기상 정보 변화로 인해 발전량 예측이 어렵다는 단점이 있다. 또한 전체 발전 설비 중 태양광의 비중이 증가함에 따라 간헐성 문제는 전력 공급의 안정성과 신뢰성에 심각한 영향을 미칠 수 있다(Son, 2023; Woo, So, Kang, & Sin, 2024). 이러한 간헐성 문제를 해결하고 전력 공급의 안정성과 신뢰성을 높이기 위해, 2021년 10월부터 재생에너지 발전량 예측 제도를 도입하기로 하였다(Yu, Kim, Jang, & Woo, 2022). 이처럼 태양광 발전량 예측은 안정성과 신뢰성 향상에 매우 중요한 요소이지만 Ahn, Lee, Oh와 Kim (2021)은 태양광 발전량을 정확하게 예측하기 위해서는 발전량과 직접적인 관련이 있는 일사량 예측이 선행되어야 할 필요성이 있다고 주장하였다. 이와 관련된 선행연구는 다음과 같다. Ekici은 기상 데이터를 활용하여 일일 일사량을 예측하고자 하였으며, 이를 위해 Least Squares Support Vector Machine(LS-SVM) 모델을 사용하였다. 일평균 온도, 최고 기온 등 다양한 입력변수를 사용하였으며, 그 결과 99.294%의 정확도를 나타냈다(Ekici, 2014). Shadab, Ahmad와 Said(2020)은 ARIMA모델을 통해 일사량을 예측하고자 하였다. 이를 위해Box Jenkins방법론 및 R패키지를 사용하였으며, 각 지역의 지리적 특성과 기후 조건에 따른 일사량 변동을 고려하였다. 그 결과 예측 정확도는 R2 = 0.92로 높게 나타나 ARIMA모델이 미래 태양광 사업에 도움이 줄 것이라 주장하였다. Al-Hajj, Assi와 Fouad(2019)는 일사량 예측을 위해 Stacking을 기반으로 한 앙상블 모델을 사용하였으며, Sliding window를 통하여 전처리를 진행하였다. 그 결과 앙상블 모델이 각각 모델 대비 더 높은 정확도를 가진 것으로 나타났다. Wang, Zhang, Zhang, Zhou와 Wu(2024)는 LSTM-BP(Long Short-Term Memory - Back Propagation)을 통해서 일사량을 보다 정확하게 예측 하고자 하였으며, 대기광학을 기반으로 하기 때문에 구름의 비율, 반사율, 에어로졸 광학두께 등을 고려하였다. 그 결과 흐린 날씨에서 기존LSTM대비 우수한 성능이 나타났다. Chung(2020)은 다중피드 포워드 신경망을 통하여 일사량 및 태양광 생산량을 예측하고자 하였으며, 예측을 위해 전날 기상 조건들을 사용하였다. 그 결과 예측 오차 값이 계절에 따라 다양하게 나타났으며, 날씨 변화에 따른 일사량 변화를 예측하지 못해 계절적 특성 변화에 따라 예측 모델 최적화가 필요하다고 주장하였다. Krishnan과 Kumar (2024)는 다양한 기후대에서 일사량을 예측하기 위해 Gradient Boost을 기반으로 한 앙상블 모델을 사용하였다. 그 결과 기존 모델들에 비해 높은 예측 정확도를 나타냈으며, 해당 모델을 통해 태양광 발전 시스템의 효율성을 극대화할 수 있지만 특정 기후대에 결과가 편향되는 등 일부 기후대에서는 모델의 예측 성능이 떨어질 수 있다고 주장하였다. 이처럼 다양한 머신러닝 모델을 활용한 일사량 예측과 관련된 연구는 많은 연구자들이 진행하고 있으며, 많은 발전을 거듭하였다. 그러나 인공지능 기술 고도화로 인해 활용 빈도가 증가함에 따라 인공지능 오류의 영향도 커지고 있다. 특히, 모델이 학습하지 않은 데이터에 직면했을 때 예측 성능이 저하될 수 있으며, 이는 태양광 발전량 예측의 정확성과 신뢰성에 직접적인 영향을 미칠 수 있다. 이에, 예측 모델 개발 초기 단계에서 불확실성을 정량화하고 이를 적절히 처리함으로써 모델의 신뢰성을 향상 시키는 것은 매우 중요하다. 그러나 불확실성 평가에 대한 기준이 모호하며, 이에 대한 표준이 성립되지 않았다는 한계점이 있다(Sin & Hwang, 2022). 따라서 본 연구에서는 머신러닝을 활용하여 태양광 발전량과 밀접하게 관련된 일사량을 예측하고, 데이터 유사성 기반의 귀납적 추론을 통해 예측 모델의 불확실성을 감소시키고 신뢰성을 증대시키는 것을 목표로 한다. 이를 통해 모델의 예측 정확도를 높이고, 다양한 기상 조건에서도 안정적으로 태양광 발전량을 예측할 수 있는 방법을 제시하고자 한다.
2. 인공지능에서의 불확실성
불확실성은 모델의 구조나 학습 과정에서 발생하는 것으로 Aleatoric과 Epistemic으로 구분할 수 있으며, 본 연구에서는 Epistemic을 해결하는 것에 초점을 맞추었다. Aleatoric의 경우 데이터 자체가 내포한 불확실성을 의미한다. 추가 데이터를 통해 불확실성을 감소시킬 수 없으며, 모든 데이터에서 같은 값을 가지는 Homoscedastic와 각 데이터에 따라 다르게 발생하는 Heteroscedastic으로 구분된다. 또한 내재적 불확실성이 높은 데이터는 모델의 오류, 학습 속도 및 품질을 저해하는 요인이 된다(Sin & Hwang, 2022). Epistemic의 경우 데이터의 수집 과정에서 사용자의 오용, 측정 오류 등 통제 불가능한 외부 요인에 기인하며, 관점으로는 Bias, Variance and Similarity로 나뉜다. 머신러닝 모델의 학습 능력 개선, 최적화 변경, 매개변수 조정, 학습 데이터 수집 등 일반화 오차를 줄임으로써 감소시킬 수 있으며, 이는 예측 모델의 성능과 직결된다. Epistemic이 높은 데이터의 경우 학습 과정에서 학습 속도 및 성능 저하에 큰 요인이기 때문에 예측 모델의 성능 및 신뢰도를 위해서 중요한 확인 요소이다(Sin & Hwang, 2022).
3. 연구 방법
3.1. 수집한 데이터의 종류와 특성
대한민국은 작은 국토 면적에도 불구하고 각 지역마다 다양한 기온 특성이 나타난다. 중위도 온대성 기후에 위치하여 봄, 여름, 가을, 겨울 사계절 특성을 가지고 있다. 봄과 가을의 경우 이동성 고기압의 영향으로 밝고 건조하며, 여름은 북태평양 고기압의 영향으로 더운 날씨를 나타내고 겨울에는 대륙성 고기압으로 인해 춥고 건조한 날씨를 나타낸다. 또한, 남북 방향으로 길게 늘어난 국토와 70% 이상을 차지하는 산악지형으로 인해 남북 간의 기온 차이가 크고 고도에 따른 기온 차도 상당히 크게 나타난다(Korea Meteorological Administration; Park & Ahn, 2023). 본 연구에서는 대한민국 기상청에서 제공하는 ASOS(Automated Synoptic Observing System)를 사용하였다. 학습 데이터의 경우 대전, 충청북도, 부산지역을 대상으로 2018.01.01~2020.12.31의 데이터를 수집하였으며, 테스트 데이터의 경우 인천지역으로 2021.01.01.~2021.12.31의 데이터를 수집하였다. 각 지역별 수집된 데이터는 1시간 단위이며, 이는 Table 1과 같다. 대전과 충청북도는 내륙에 위치하여 대륙성 기후의 특성을 보이며, 부산은 해양성 기후의 영향을 많이 받는 지역으로, 서로 다른 기후 조건에서 모델 결과를 확인할 수 있다. 또한 학습 데이터와 테스트 데이터의 지역을 다르게 설정한 이유는 본 연구에서 개발한 모델의 일반화 능력을 평가하기 위함으로 동일한 지역의 데이터만 사용하여 학습 및 예측하는 경우 과적합 문제가 발생할 수 있다. 즉, 학습 및 테스트 지역을 구분함으로써 다양한 기후 조건에서도 개발된 모델이 일관된 성능을 유지할 수 있을 것으로 기대할 수 있다.
Table 1.
Comparison of Meteorological Data Across Regions
3.2. Artificial Neural Networks
Artificial Neural Networks(ANNs)은 생물학적 신경망의 복잡한 구조와 기능을 모방하기 위해 만들어진 정교한 수학적 모델을 나타내며, 모든 인공신경망의 핵심에는 Artificial Neuron이 있다. 가장 단순한 형태의 ANN중에는 두 개의 입력과 하나의 출력으로 구성된 Perceptron이 있으며, 두개 이상의 Hidden Layer가 있는 Multilayer Perceptions(MLPs)이 있다. 이러한 모델은 Multiplication, Summation그리고 Activation이라는 세가지 기본 원칙에 따라 작동한다. Artificial neuron 내에서 입력 값은 해당 입력 값에 할당된 가중치에 의해 개별적으로 곱해지며, 가중치가 적용된 입력 값들은 Bias와 함께 Summation함수를 통해 합산된다. 분류 및 예측에 효과적으로 알려진 MLPs는 중요한 기술 중 하나로 자리잡고 있다(Grossi & Buscema, 2007; Krenker, Bester, & Kos, 2011).
3.3. Pearson Correlation Coefficient 및 변수 선정
상관 계수를 약함, 중간 또는 강함으로 분류하는 방법은 다양하지만, 이러한 기준은 일관성이 없어 적용 시 신중할 필요가 있다. 선행 연구들을 통하여 0.1미만의 경우 매우 약한 관계를, 0.9 이상의 경우 매우 강한 관계를 나타낸다는 것이 나타났지만, 해당 값들의 사이에 위치한 값의 경우 여전히 해석에 논란이 있다. 예를 들어 상관 계수 값이 0.65인 경우 기준에 따라 보통 또는 좋음의 관계로 간주될 수 있으며, 0.39는 약함 0.4는 보통으로 분류하는 것 역시 임의적이다. 따라서 본 연구에서는 선행 연구를 기반으로 하여, 유의미한 관계를 나타내는 상관관계 값을 0.3으로 분류하였다(Cohen, 2013; Schober, Boer, & Schwarte, 2018). 이에 따라 변수를 선정하였고 출력변수의 경우 테스트 지역의 일사량, 입력변수의 경우 Table 2와 같다.
Table 2.
Correlation Between Input and Output Variables
3.4. 데이터 유사성 평가 방법
본 연구에서는 3.1절에 언급한 지역들을 대상으로 Euclidean distance, Cosine similarity, Manhattan distance를 사용하여 유사성을 비교하였으며, 해당 값들을 바탕으로 학습 지역과 테스트 지역의 데이터를 비교하였다. 수식은 식(1), (2), (3)과 같으며, 입력변수 별 데이터 유사성은 Table 3과 같다.
Table 3.
Data Similarity by Input Variables
Euclidean Distance: 가장 일반적으로 사용되는 방법으로 두 패턴 사이의 직선거리를 측정하는 것을 의미하며, Scale 또는 Magnitude에 대해 민감하다. 값의 크기가 작을수록 유사성이 높다(Xia, Zhang, & Li, 2015).
Cosine Similarity: 일반적으로 고차원의 공간에서 정보 검색이나 데이터 마이닝과 같은 작업을 수행할 때 사용되는 방법 중 하나이다. 작은 변화에도 민감한 Euclidean distance와 달리 두 벡터의 방향에 더 중점을 가지고 있다. 이 각도가 작을수록 유사성이 높다(Xia et al., 2015).
Manhattan Distance: 실생활에서 사용되는 거리 측정 방법 중 하나로 Secure multiparty computation이다. 주로 표준 좌표계에서 두 점의 절대 거리를 계산하는데 사용하고 각 차원의 절대값의 차이 합으로 계산된다(Liu et al., 2022).
3.5. 시나리오 선정
본 연구에서는 데이터의 유사성이 예측에 미치는 결과를 확인하기 위하여 8가지의 시나리오를 선정하였다. 각각의 시나리오는 3.1절에서 언급한 학습 데이터에 사용한 3가지 지역과 데이터 유사성이 가장 높은 1개의 가상 지역으로 구성하였으며, 가상 지역의 경우 Synthetic로 명명하였다. 또한 Synthetic의 경우 Table 3에 나타난 바와 같이 데이터 유사성 판단 결과에 따라 기온과 지면 온도는 대전 지역의 데이터를 사용하였으며, 풍속, 습도 그리고 일조는 충청북도 지역의 데이터를 활용하였다. 시나리오의 경우 지역 외에도 Layer의 관점에서도 구분하였으며, 이는 Table 4와 같다.
Table 4.
Scenario Based on Layer and Region
| Scenario | Layer | Region |
| Scenario 1 | 1 | Daejeon |
| Scenario 2 | Chungcheong Buk-do | |
| Scenario 3 | Busan | |
| Scenario 4 | Synthetic | |
| Scenario 5 | 2 | Daejeon |
| Scenario 6 | Chungcheong Buk-do | |
| Scenario 7 | Busan | |
| Scenario 8 | Synthetic |
3.6. 예측 모델 개발 과정
본 연구에서는 학습 데이터를 75% 테스트 데이터를 25%로 구성하여 학습 및 예측을 진행하였으며, 예측 정확도가 뛰어난 모델 구조를 찾기 위해 Hidden layer는 1~2개, Hidden node는 10~15개 범위 내에서 변경하며, 각각의 모델 구조를 비교하였다. 학습의 경우 200번 반복하였으며, Local minima와 Overfitting을 완화하기 위하여 Batch size의 경우 128로 설정하였다. 또한 정규화의 경우 학습 및 예측에 중요한 역할을 담당하기 때문에 MinMaxScaler와 QuantileTransformer 정규화 방법을 비교하였다. MinMaxScaler은 데이터셋을 0에서 1사이의 범위로 변환하여 데이터 값의 크기와 분포를 조정하며, 데이터가 일정한 범위 내에 위치한다. 그러나 StandardScaler와 마찬가지로 이상치 값에 민감하여 이상치 값이 존재하는 경우 학습 및 예측에 부정적인 영향을 미치기도 한다(Scikit-learn). QuantileTransformer 은 특성을 균일하거나 정규 분포를 따르도록 변환하며, 특정 특성에 대해 가장 빈도가 높은 값을 분산시키는 경향이 있다. 즉, 데이터셋을 효과적으로 분산시키는 동시에 이상치 값에 대한 영향을 감소시켜 높은 신뢰성을 보여준다(Scikit-learn).
3.7. 예측 모델 성능 평가
본 연구에서는 개발된 모델간 예측 성능을 비교하기 위하여 MAE, CV(RMSE), NMBE and R2를 성능 평가 지표로 사용하였다. CV(RMSE) 및 NMBE는 모델의 불확실성 측정을 위해 ASHRAE guideline 14-2014에서 제안하는 방법이다. RMSE는 예측의 정확도에 대한 척도를 제공하고 CV(RMSE)는 정규화 됨에 따라 영역 간의 비교가 가능하다. NMBE의 경우 모델의 편향을 측정하는데 적합한 측정 기준이며, MAE는 두 값의 차이를 절대값으로 제공한다. 평가 지표들의 수식은 (4) to (8)와 같다(A.S.H.R.A.E, 2014; Ehuia-Oller, Martinez-Marino, Granada-Alvarez, & Febrero-Garrido, 2021; Park, Hong, Yeon, Seo, & Lee, 2023).
또한 시나리오별 예측 값들의 분포를 분석하였다. 이를 위해 사용한 주요 지표로는 Q1, Q2 및 Q3가 있으며, Q1은 하위 25%에 해당하는 값, Q2는 데이터를 정렬하였을 때 중앙에 위치한 값, Q3는 상위 25%에 해당하는 값을 나타낸다. 이러한 평가 지표들을 통해 예측 모델의 성능 및 시나리오별 예측 값 분포를 종합적으로 평가할 수 있다.
4. 예측 결과 및 시나리오 비교 분석
4.1. 정규화 방법에 따른 예측 결과 비교
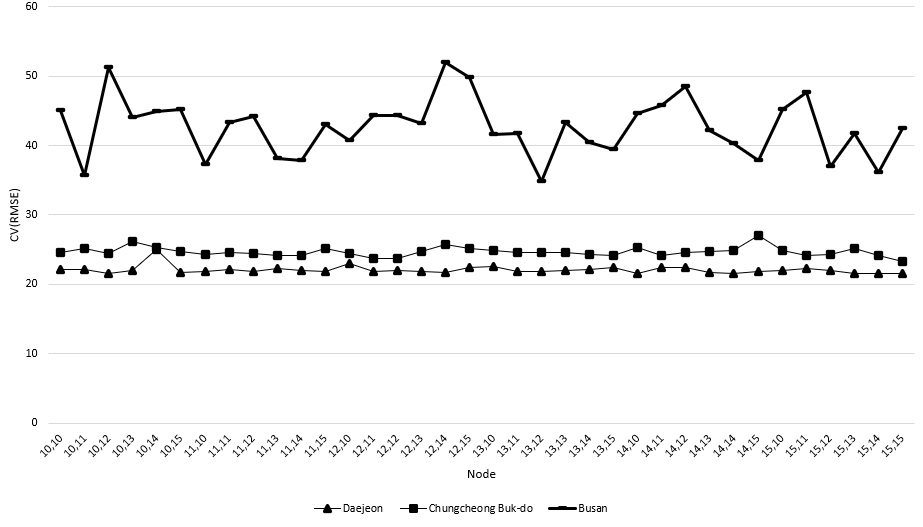
본 연구에서는 3.5절에서 언급한 바와 같이 Layer, Node 및 정규화를 적용하여 총 252개의 다양한 모델 구조를 비교하였다. Figure A1, A2, A3, A4에 나타난 바와 같이 부산의 경우 Layer, Node의 수에 상관없이 CV(RMSE) 값이 높게 나타났다. 이는 해당 지역의 데이터가 테스트 지역의 데이터에 적합하지 않다는 것을 의미한다. 다른 두 지역의 경우 Layer나 Node 개수 변화에 따라 CV(RMSE)가 변화하였으나 큰 차이를 나타내지는 않았다. Figure 1의 경우 Layer개수 및 정규화 방법에 따라 우수한 CV(RMSE)결과를 나타낸 그래프이며, 모든 지역에서 QuantileTransformer가 더 우수한 결과를 나타냈다. 가장 우수한 결과를 나타낸 지역은 Daejeon으로 Layer = 1 경우 Node = 10, Layer = 2 경우 Node = 10, 12로 CV(RMSE)는 각각 21.7%, 21.5% 이다. 수집한 데이터에 이상치 값들의 포함 여부를 알아보기 위하여 통계학에서 Empirical Rule이라고도 하는 68-95-99.7rule에 해당하는 값들 중 2표준편차 범위에 따라 각 지역들의 일사량을 살펴보았다. 그 결과 대전 = 2.57, 충청북도 = 2.43, 부산 = 2.43으로 나타나 충청북도와 부산의 경우 동일한 것으로 나타났으나, 이는 분포가 유사한 것을 의미할 뿐 데이터의 특성까지 동일하다고 보기에는 어렵다. 또한 2 표준 편차의 비율은 4.5%이나 각 지역에서 발생한 2 표준 편차보다 높은 값의 비율은 3개 지역 모두 약 7%로 학습에 사용한 데이터의 경우 이상치 값이 많은 것으로 판단된다. 이러한 이유로 이상치 값에 상대적으로 덜 민감한 QuantileTransformer가 MinMaxScaler 대비 뛰어난 예측을 한 것으로 보인다.
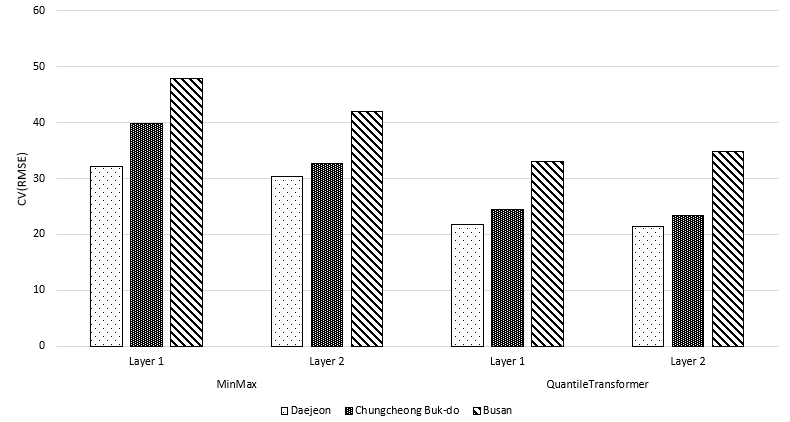
4.2. 시나리오 비교
4.2.1 시나리오별 예측 결과 비교
본 연구에서는 3.6절에 언급한 평가 지표를 기반으로 시나리오별 결과 분석을 진행하였으며, 이는 Table 5와 같다. 그 결과 기상 데이터의 유사성이 높았던 대전과 충청북도가 상대적으로 데이터의 유사성이 낮은 부산에 비해 높은 정확도를 가진 것으로 나타냈다. 평가항목 중 하나인 CV(RMSE)의 경우 대전 지역인 시나리오 1과 5가 가장 우수한 결과를 나타냈으나, NMBE의 경우 데이터의 유사성이 가장 높은 시나리오 4와 8이 가장 우수한 결과를 나타냈다.
Table 5.
Predictive Performance by Scenario
4.2.2 시간대별 오차 값 분석
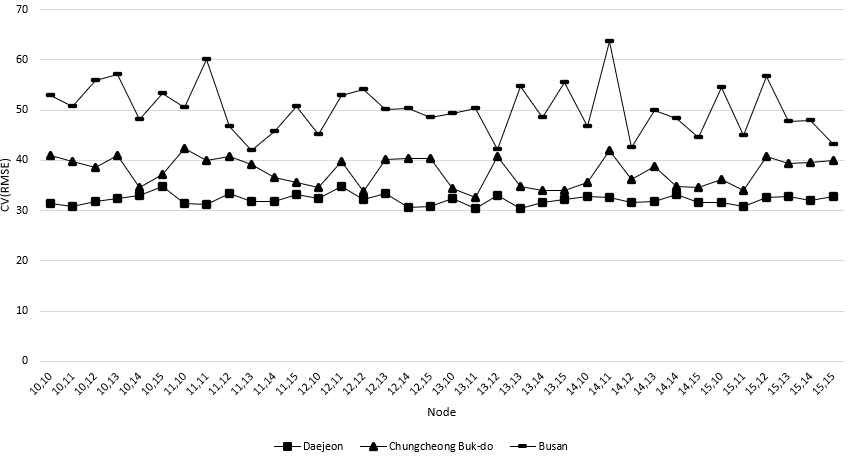
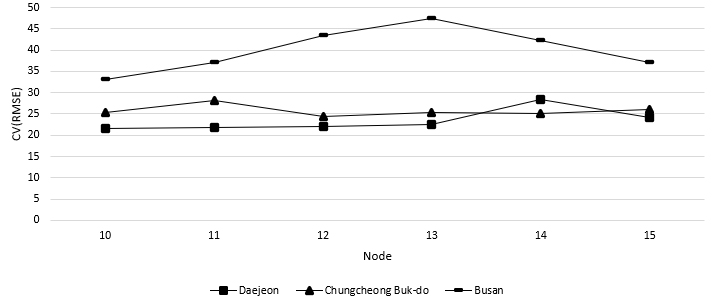
본 연구에서는 테스트 기간인 2021.01.01~2021.12.31까지 각 시간에 발생하는 평균 오차를 확인하였으며 이는 Figure 2, 3과 같다. Figure 2와 3에 나타난 바와 같이 시나리오 3과 7을 제외한 나머지 시나리오의 경우 비슷한 패턴이 나타나는 것을 확인할 수 있었다. 시나리오 3과 7의 경우 Layer 1,2 모두 10~17시 사이에 오차 값이 다른 지역 대비 큰 것으로 나타났다. 부산과 인천의 기후는 해양성 기후이기 때문에 기후적 유사성이 있을 것이라고 생각할 수 있으나, Table 3에 나타난 바와 같이 실제 두 지역의 데이터 유사성은 큰 차이가 나타났기 때문에 다음과 같은 결과가 발생한 것으로 판단된다. 또한, 모든 시나리오에서 일출 및 일몰 시간에 오차 값이 다른 시간에 비해 크게 발생한 것으로 나타났다. 이는 일출 및 일몰 시간에는 여러 기상 조건이 급격하게 변하기 때문에 정확한 예측이 어려울 수 있다는 것을 의미한다. 예를 들어, 일출 및 일몰 시간에는 대기의 안정성 및 태양의 고도가 빠르게 변하기 때문에 사용된 입력 변수인 풍속, 습도, 기온 등이 해당 시간의 예측 오차 값이 상대적으로 크게 발생한 것으로 판단된다.


4.2.3 예측값 분포 분석
본 연구에서는 각 시나리오별 예측 값들의 분포를 분석하였으며, 이는 Figure 4와 Table 6과 같다. 시나리오1의 경우 최소값과 최대값까지의 범위가 비교적 작고, 평균값 역시 상대적으로 낮은 편으로 예측 값들이 좁은 범위에 분포되어 있음을 의미한다. 시나리오 2의 경우 Q3과 최대값이 상대적으로 높은 것으로 나타났으며, 평균값 역시 다른 시나리오에 비해 높은 것으로 나타났다. 시나리오 3의 경우 Q2부터 Q3까지의 범위가 다른 시나리오에 비해 크며, 평균값도 상대적으로 큰 것으로 나타났다. 이는 예측 값들이 중간부터 높은 범위에 걸쳐 넓게 분포하고 있음을 나타낸다. 시나리오 4의 경우 시나리오 1과 비슷한 양상을 보이며, 최소값부터 최대값 까지의 범위가 비교적 좁고 평균값 역시 비교적 작은 것으로 나타났다. 이는 예측 값들이 좁은 범위에 분포되어 있음을 의미한다. 시나리오 5의 경우 다른 시나리오에 비해 평균값이 낮고 최소값과 최대값 사이의 범위가 상대적으로 작은 편이다. 이는 예측 값들이 일관되게 좁은 범위에 분포되어 있음을 의미한다. 시나리오 6의 경우 최소값부터 최대값까지의 범위가 매우 큰 것으로 나타났으나 평균값의 경우에는 상대적으로 작은 것으로 나타났다. 이는 예측의 범위가 넓은 것을 의미한다. 시나리오 7의 경우 다른 시나리오에 비해 Q2와 평균값이 큰 것으로 나타났다. 이는 중앙값과 하위 25%의 데이터에 해당하는 값들이 상대적으로 큰 것을 의미한다. 시나리오 8의 경우 시나리오 5와 마찬가지로 평균값이 낮고 최소값과 최대값 사이의 범위가 상대적으로 작은편이다. 이는 예측 값이 일정 범위 내에 집중되어 있음을 의미한다.
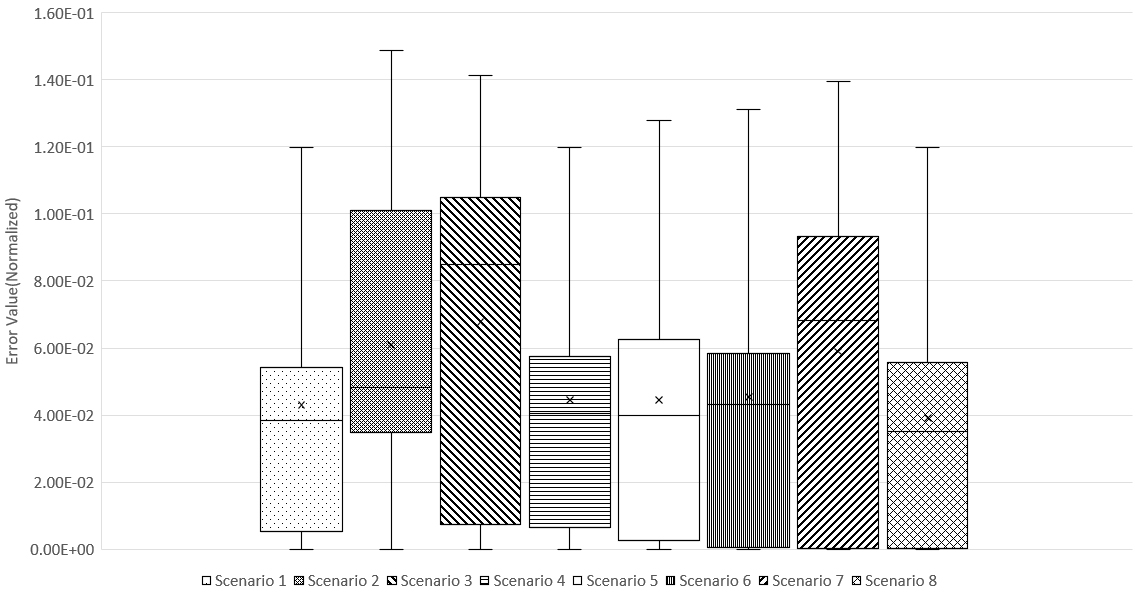
Table 6.
Summary of Quartiles by Scenario
5. 결 론
본 연구에서는 데이터의 유사성 분석을 기반으로 예측 모델의 불확실성을 감소시키고, 이를 통해 모델의 신뢰성을 확보하는 것에 중점을 두고 있다.
각 시나리오를 비교 분석한 결과, 시나리오 1, 4, 5, 8이 상대적으로 뛰어난 예측이 가능한 것으로 나타났다. 이 중 시나리오 8은 MAE가 가장 낮고 NMBE와 CV(RMSE)또한 낮은 편으로 다른 시나리오에 비해 일관된 예측을 제공함과 동시에 R2역시 0.95로 높은 상관성을 나타내 신뢰할 수 있는 예측을 제공할 수 있음을 나타냈다. 또한 최소값, 분포 및 평균 역시 낮은 것으로 나타나 해당 시나리오가 가장 뛰어난 모델임을 알 수 있다.
이러한 연구결과를 바탕으로 스마트 시티와 신재생 에너지 등 머신러닝을 기반으로한 예측을 하는 경우 데이터의 유사성과 불확실성을 적절히 고려한 모델의 활용이 필요함을 의미한다. 더불어 모델의 개선과 데이터의 품질 향상을 통해 모델 예측 정확도와 안정성 역시 높일 필요가 있다. 그러나 본 연구의 결과를 기반으로 모든 지역에 적용하는 데에는 한계가 있을수 있으며, 새로운 환경에 맞춰 데이터 유사성 검증 및 모델 조정이 필요하다.

Abbreviations
ANN: Artificial Neural Network
PCC: Pearson Correlation Coefficient
CV(RMSE): Coefficient of Variation of the Root Mean Squared Error
ASHRAE: American Society of Heating, Refrigerating and Air-conditioning Engineers
RMSE: Root Mean Square Error
MAE: Mean Absolute Error
NMBE: Normalized Mean Bias Error
R2: R-square
Q1: First Quartile(Lower quartile)
Q2: Median
Q3: Third Quartile(Upper quartile)
