

1. 서 론
1.1. 연구 배경
1.2. 핵심 용어 정의
1.3. 연구 목적 및 기여
2. 이론적 배경 및 선행 연구
2.1. 디지털트윈과 농업 적용
2.2. 메타버스 기반 시뮬레이션
2.3. ML 기반 농업 예측과 한계
2.4. 본 연구의 차별성
3. 연구 방법
3.1. 시뮬레이터 개발 프로세스
3.2. 사용자 인터페이스 및 경험(UX) 설계
3.3. 시뮬레이션 구조 설계(디지털 트윈 + 예측 통합 모델)
3.4. 데이터 구성(입력/출력 항목) 및 출처
3.5. 데이터 전처리 및 보정 기준(단위/이상치/결측)
3.6. 예측 모델(XGBoost) 및 비교 모델
3.7. 성능 평가 지표(RMSE, R²) 및 통계적 유의성 검정
4. 연구 결과
4.1. 상관관계 분석 결과
4.2. 예측 모델 성능(정량 지표 제시)
4.3. 3개 온실(동) 전체 실증 결과 및 통계 검정
4.4. 시뮬레이터 효과(농가 적용 관점)
5. 논 의
6. 결 론
1. 서 론
1.1. 연구 배경
농업은 기후 변화, 에너지 비용상승, 노동력 부족 등 구조적 도전에 직면해 있으며, 생산성과 지속가능성의 동시 달성이 중요한 과제로 부상하였다. 이에 따라 스마트팜을 중심으로센서 기반 데이터 수집과 환경 제어가 확대되면서, 데이터 기반 농업(data-driven agriculture)에 대한 관심이 증가하고 있다. 데이터 기반 농업은 환경·생육 데이터를 정량적으로 분석하여 재배 전략을 최적화함으로써 생산성과 품질을 개선하는 접근이다. 그러나 현장 적용 관점에서 중요한 것은 ‘예측값 자체’ 뿐 아니라, (1) 실제 물리 환경과의 동기화, (2) 결과에 대한 해석 가능성, (3) 운영자가 조건을 바꾸며 반복 실험할 수 있는 상호작용성이다. 이러한 요건이 충족되지 않으면, 예측 모델은 실무에서 ‘참고용 숫자’로 머물 가능성이 높다.
디지털 트윈은 물리 시스템의 상태를 디지털 공간에 동기화하여 분석·예측·최적화를 가능하게 하는 기술로, 제조·전력 등 다양한 산업에서 활용되고 있다(Fuller, Fan, Day, & Barlow, 2020; Abo-Khalil, 2023). 농업에서도 디지털 트윈은 온실 환경 제어, 생육 상태 모니터링, 운영 최적화에 적용될 수 있으며(Nasirahmadi & Hensel, 2022), 스마트팜의 고도화를 위한 핵심 기술로 평가된다(Rimma, Marina, Olga, Andrey, & Albina, 2020). 또한 메타버스 기반 3D 가상 환경은 복잡한 시스템을 직관적으로 이해하고 사용자가 직접 조작하며 반복 실험할 수 있어 교육·훈련과 운영 의사결정 지원에 유리하다(Weersink, Fraser, Pannell, Duncan, & Rotz, 2018).
그러나 기존 ML 기반 농업예측 연구는 오프라인 분석 중심의 접근이 많았으며, 디지털 트윈 기반의 실시간 동기화 및 메타버스 기반 상호작용을 통합한 구조는 상대적으로 부족하였다. 이에 본 연구는 디지털 트윈과 메타버스를 통합한 농업 시뮬레이터를 설계하고, XGBoost 기반 예측 모델을 결합하여 실증 데이터 기반 효과성을 검증하고자 한다.
1.2. 핵심 용어 정의
본 연구에서 ‘농업 메타버스 시뮬레이터(Agricultural Metaverse Simulator)’란, (a) 실제 온실(스마트팜) 환경의 센서·생육 데이터를 기반으로 구축된 디지털 트윈 모델을, (b) 메타버스(3D 가상 환경)에서 구현하고, (c) 머신러닝 기반 생육 예측 모델을 통합하여, 사용자가 재배 조건(예:온도·습도·CO₂·양액 등)을 조정하면서 생육/생산 지표 변화를 실시간 예측·시각화·비교할 수 있도록 설계된 시스템을 의미한다. 이는 단순한 교육용 가상 체험 도구를 넘어, 실제 농가 운영 의사결정 지원과 교육·훈련 확장성을 동시에 목표로 한다.
1.3. 연구 목적 및 기여
본 연구의 목적은 다음과 같다.
1) 디지털 트윈 메타버스 기반농업 시뮬레이터의 개발 프레임워크를 제시한다.
2) XGBoost 기반 회귀예측 모델을 통합하여 생육·생산 지표를 예측한다.
3) 3개 온실 동 실증 데이터를통해 시뮬레이션 재현성과 통계적 유의성을 검증한다.
4) 기존 ML 기반 농업 예측/시뮬레이션대비 차별점, 장단점, 농가 적용 기대 효과를 논의한다.
2. 이론적 배경 및 선행 연구
본 절에서는 디지털 트윈, 메타버스 기반 시뮬레이션, 그리고 ML 기반 농업 예측 연구를 검토하고, 본 연구의 이론적·방법론적 차별성을 명확히 한다.
2.1. 디지털트윈과 농업 적용
디지털 트윈은 물리 시스템과 디지털 모델을 연결하여, 현재 상태를 동기화하고 미래 상태를 예측·평가할 수 있게 한다(Fuller et al., 2020). 농업 분야에서는 온실 내부 환경(온도, 습도, CO₂, 일사량 등)과 생육 반응을 연결하는 모델을 구축하여, 환경 제어 최적화와 이상 상황 조기 탐지에 활용할 수 있다(Nasirahmadi, & Hensel, 2022). 또한 controlled environment agriculture(CEA)에서 디지털 트윈 아키텍처를 적용하여 생산성 최적화를 시도한 연구도 보고되었다(Chaux, Sanchez-Londono, & Barbieri, 2021).
2.2. 메타버스 기반 시뮬레이션
메타버스 환경은 3D 시각화와 상호작용을 통해 복잡한 시스템의 이해를 돕고, 반복 실험 기반 학습을 가능하게 한다. 농업에서는 장비 운용, 환경 제어, 재배 시나리오 학습 및 현장 교육에 적용 가능하며, 특히 경험 기반 학습(learning-by-doing) 관점에서 교육 효과를 강화할 수 있다(Weersink et al., 2018).
2.3. ML 기반 농업 예측과 한계
ML 기반 예측 모델은 생육지표 추정 및 수확량 예측에 활용되어 왔다. 다만 예측 모델이 실제 운영 의사결정으로 전환되기 위해서는, 예측 결과를 ‘언제/어디서/어떻게’ 활용할지에 대한 시스템 설계가 필요하다. 즉, 데이터 수집–전처리–예측–시각화–의사결정(액션)으로 이어지는 통합 파이프라인이 요구된다. 또한 입력 변수간 상관 및 공선성 문제, 센서 오류·결측 등의 현실적 이슈가 모델 성능에 영향을 미치므로, 전처리 기준과 검증 절차의 명확한 제시가 필요하다.
2.4. 본 연구의 차별성
본 연구의 차별성은 기존 ML 기반 예측·시뮬레이션 연구와 달리 디지털 트윈-메타버스 환경과 XGBoost를 결합하여 예측·동기화·상호작용 기반 의사결정을 지원하고, 3D 시각화 및 실증 온실 3개 동 전체 결과에 대한 통계 검증과 상관관계·특성 중요도 분석까지 확장했다는 점에 있다(Table 1).
Table 1
Differentiation of this study
3. 연구 방법
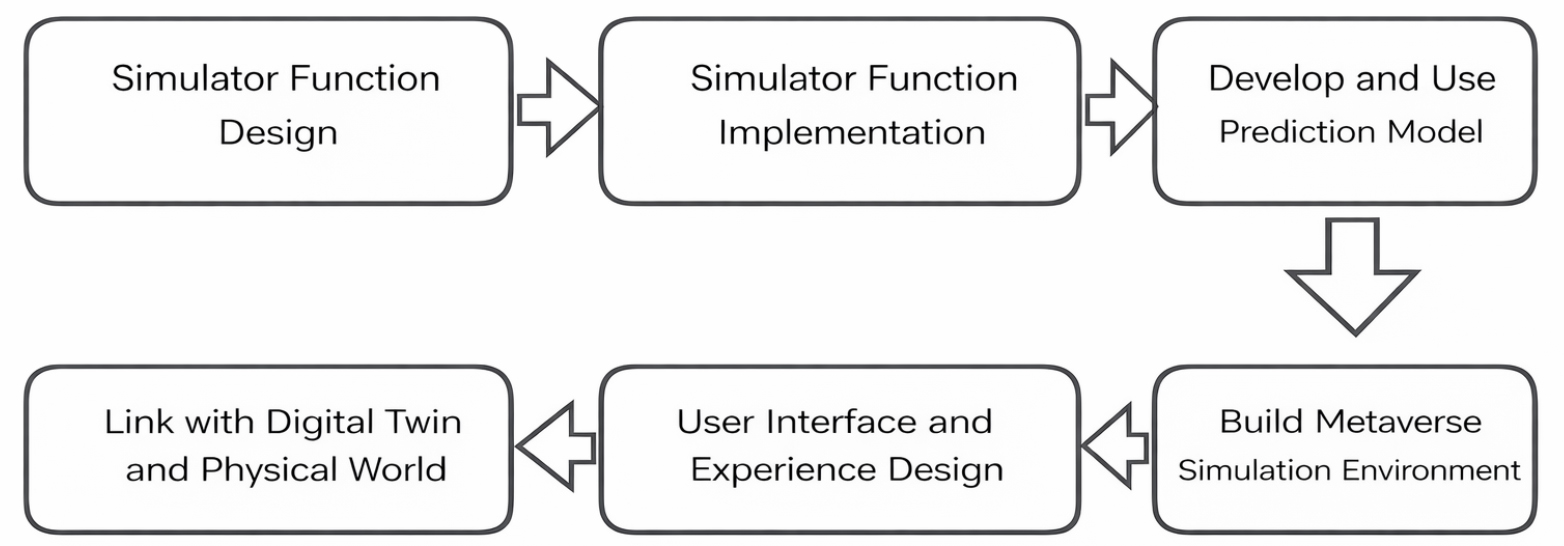
3.1. 시뮬레이터 개발 프로세스
시뮬레이터 개발은 (1) 기능 설계, (2) 기능 구현, (3) 예측 모델 도출 및 활용, (4) 메타버스 시뮬레이션 환경 구축, (5) 사용자 인터페이스 및 경험(UX) 설계, (6) 디지털 트윈 및 실물세계 연동 단계로 구성하였다. 이는 ‘데이터 수집→예측→시각화→사용자 실험’의 흐름을 하나의 시스템으로 구현하기 위한 절차이며, 각 단계는 반복 개선(iteration)을 통해 통합되었다(Figure 1).
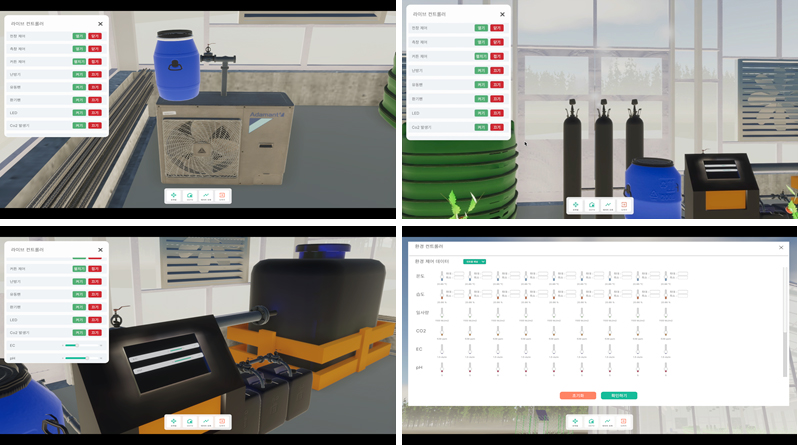
3.2. 사용자 인터페이스 및 경험(UX) 설계
UI/UX의 핵심 목적은 사용자가 예측값을 단순 관찰하는 것을 넘어, 운영 의사결정에 활용하도록 돕는 것이다. 따라서 UI는 (1) 현재 생육 상태 요약(핵심 지표 카드/요약), (2) 입력 변수 시계열(온도·습도·CO₂·일사량·EC·pH 등) 시각화, (3) 시나리오 입력(예: 목표 온도/CO₂ 상향, 양액 EC 조절 등), (4) 예측 결과 비교(기준 시나리오 vs 변경 시나리오), (5) 이상치/센서 오류 알림 및 데이터 품질 표시를 포함하도록 설계하였다. 이러한 구성은 ‘예측→해석→행동’으로 이어지는 의사결정 루프를 구현하기 위한 것이다(Figure 2).
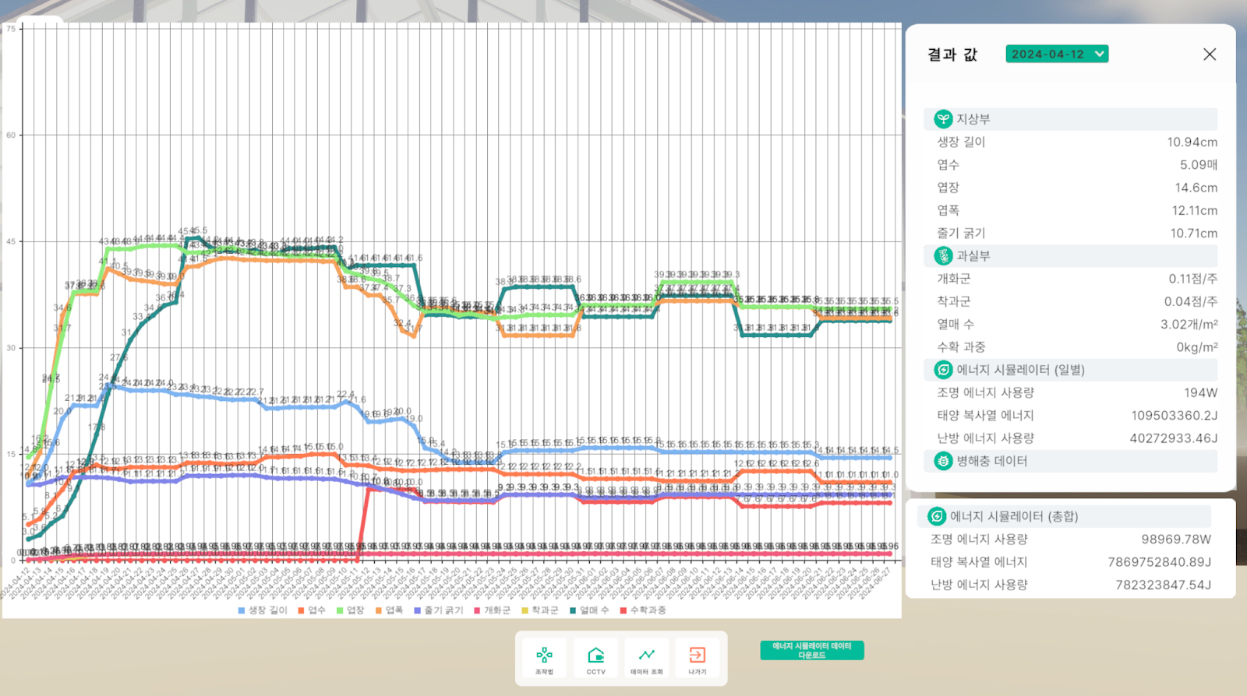
3.3. 시뮬레이션 구조 설계(디지털 트윈 + 예측 통합 모델)
시뮬레이션 구조는 디지털 트윈 계층과 예측 모델 계층의 결합으로 설계하였다. 디지털 트윈 계층은 센서 데이터의 시간 정렬(time alignment)과 상태 업데이트(state update)를 수행하며, 예측 모델 계층은 전처리된 입력 변수를 기반으로 생육/생산 지표를 예측한다. 메타버스 환경에서는 예측 결과가 3D 객체(작물 성장 상태) 및 대시보드 형태로 시각화되며, 사용자는 조건을 변경하고 그 결과를 반복 비교할 수 있다. 본 구조는 CEA 환경에서 디지털 트윈 기반 최적화 연구(Chaux et al., 2021)와 유사한 통합 지향성을 갖되, 메타버스 기반 사용자 상호작용을 강조한다는 점에서 차별성이 있다(Figure 3).
3.4. 데이터 구성(입력/출력 항목) 및 출처
데이터는 농촌진흥청 공개 토마토 데이터와 실증 재배 온실 데이터를 활용하였다. 예측 모델의 입력 변수는 온실 환경 및 제어 관련 7종이며, 출력(예측 목표) 변수는 생육/생산 관련 11종으로 구성하여 총 18개 변수(입력 7 + 출력 11)를 사용하였다(데이터 샘플은 253 rows × 18 columns 형식으로 구성된다.) (Table 2, Table 3).
Table 2
Input Item Data Specification
Table 3
Output Item Data Specification
3.5. 데이터 전처리 및 보정 기준(단위/이상치/결측)
첫째, 단위는 °C, %, ppm, Wh/cm², EC, pH 등으로 통일하였다. 둘째, 센서 오류 및 통신 문제로 발생하는 이상치(outlier)는 변수별 분포를 확인한 후 IQR(Interquartile Range) 기준(Q1−1.5×IQR 미만 또는 Q3+1.5×IQR 초과)을 적용하여 제거하거나 보정하였다. 셋째, 결측치는 결측 구간 길이에 따라 단기 결측은 선형 보간, 장기 결측은 구간 제거 원칙을 적용하였다. 전처리 과정은 학습/검증 데이터에 동일하게 적용하여 편향을 최소화하였다.
3.6. 예측 모델(XGBoost) 및 비교 모델
예측 모델은 XGBoost(Extreme Gradient Boosting)를 사용하였다. XGBoost는 부스팅 기반 앙상블 학습으로 비선형 관계를 효과적으로 모델링할 수 있으며, 규제(reg) 및 결측 처리 등 실무적 강점을 가진다. 객관적 비교를 위해 비교 모델(예: Random Forest 등)을 동일한 데이터 분할 및 전처리 조건에서 함께 평가하였다. 비교 모델의 상세 결과는 지면 제한에 따라 핵심 지표 중심으로 요약하고, 본문에는 XGBoost 결과를 중심으로 제시한다.
3.7. 성능 평가 지표(RMSE, R²) 및 통계적 유의성 검정
회귀 성능 평가지표로 RMSE(Root Mean Squared Error)와 R²(Coefficient of Determination)를 사용하였다. RMSE는 예측 오차의 크기를 동일 단위로 해석할 수 있어 운영 관점에서 유용하며, R²는 모델이 종속변수의 변동을 얼마나 설명하는지 나타낸다.
또한 실증 재배 온실 3개 동 전체에 대해 시뮬레이션 결과와 실측 데이터 간 차이를 검증하기 위해 대응표본 t-검정을 수행하였다. 정규성 가정이 충족되지 않는 경우 Wilcoxon signed-rank test를 추가로 적용하였다.
4. 연구 결과
4.1. 상관관계 분석 결과
상관관계 분석은 (1) 변수 선택의 타당성 확보, (2) 주요 환경 요인의 영향 해석, (3) 다중공선성 가능성 점검을 목적으로 수행하였다. 상관관계 히트맵(Figure 4)은 입력 변수와 출력 변수 간 관계를 시각적으로 제시하며, 이 결과는 이후 특성 중요도 해석과 결합하여 운영 의사결정에 활용 가능한 근거를 제공한다.
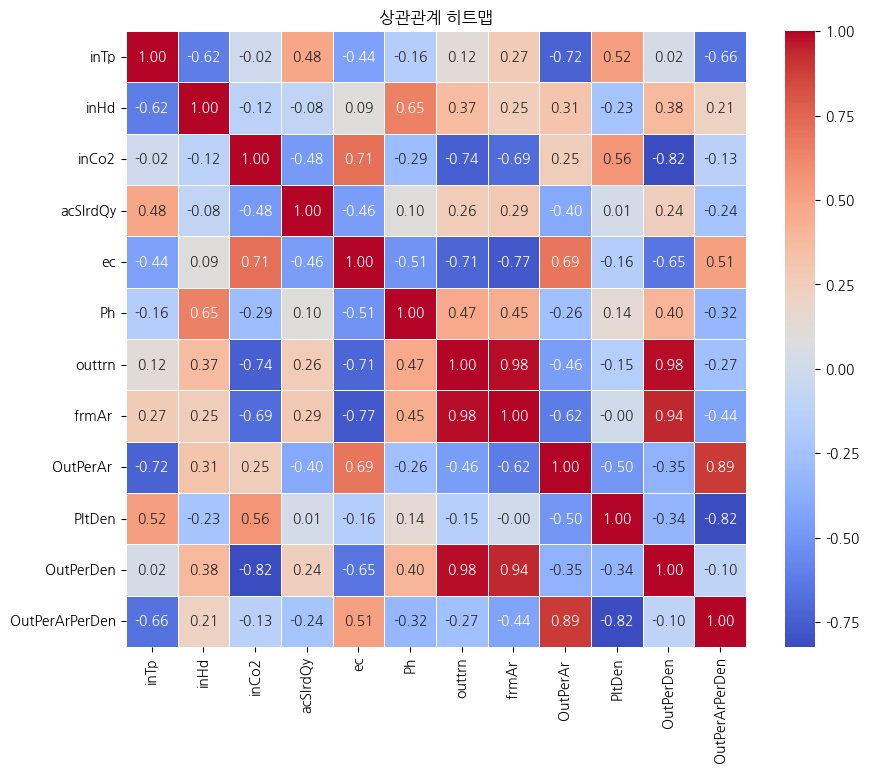
분석 결과, 일부 환경 변수(예: CO₂, 일사량, 온도 등)는 특정 생육 지표와 비교적 높은 상관을 보였고, 일부 지표는 다른 환경 변수들과의 관계가 약하거나 비선형적 반응을 시사하였다. 이러한 결과는 ‘단일 변수의 단순 효과’보다는 ‘복합 조건’이 생육에 영향을 미칠 수 있음을 암시하며, 비선형 모델(XGBoost) 채택의 근거로도 활용될 수 있다.
4.2. 예측 모델 성능(정량 지표 제시)
정량 결과를 종합하면, 착과수(frtstCo)와 엽수(lefCunt)는 전반적으로 상대적으로 높은 설명력을 보였으며(R² 양의 값), 개화군(flanGrupp)도 소규모 오차(RMSE)와 함께 일정 수준의 설명력을 보였다. 반면 생장길이(grwLt), 줄기굵기(stemThck), 엽폭(lefBt) 등 일부 변수는 R²가 0에 가깝거나 음수로 나타났다. 이는 (1) 해당 지표가 입력 변수만으로 충분히 설명되지 않거나, (2) 데이터 분포의 편향·변동성, (3) 학습 데이터 범위의 제한, (4) 농가/동별 관리 방식 차이 등으로 인해 예측 불확실성이 커질 수 있음을 의미한다.
4.3. 3개 온실(동) 전체 실증 결과 및 통계 검정
실증 검증은 (a) 시뮬레이션 12주 결과(표/그래프)와 (b) 실측 데이터의 비교를 통해 수행되었다. 특히 1동의 경우 주요 지표가 약 90% 수준에서 일치하는 것으로 보고되었으며, 2동과 3동에서도 전반적인 추세가 유사하게 나타나 재현성 가능성을 확인하였다. 다만 일부 변수에서는 동별 편차가 존재하였는데, 이는 센서 품질, 결측 구간, 재배 관리 변동(양액/온도 설정), 미반영 외생 변수(병해충, 작업 패턴 등)의 영향 가능성이 있다.
통계적 유의성 검정은 시뮬레이션 결과와 실측 데이터의 차이를 정량적으로 검증하기 위해 수행하였다. 대응표본 t-검정을 기본으로 적용하고, 정규성 가정이 충족되지 않는 경우 Wilcoxon signed-rank test를 병행하였다. 검정 결과는 주요 생육 지표에서 유의수준 0.05 기준 통계적으로 유의한 차이가 나타나지 않는 것으로 보고되며(p-value > 0.05), 이는 시뮬레이터가 실측 데이터를 합리적 수준에서 재현할 수 있음을 시사한다. 단, 통계 검정은 데이터 품질(결측/이상치) 및 표본 수의 영향을 받으므로, 향후 장기 실증과 더 큰 표본의 확보가 필요하다(Table 4).
Table 4
Predictive model performance
4.4. 시뮬레이터 효과(농가 적용 관점)
본 시뮬레이터는 예측 정확도 향상뿐 아니라, 메타버스 환경에서의 시나리오 실험을 통해 운영 의사결정(관수·환기·차광·CO₂ 공급 등) 개선에 활용될 수 있다. 구체적으로 운영자는 (1) 목표 CO₂ 상향 시 착과수 변화, (2) 일사량/온도 조건 변화에 따른 생장길이 추세, (3) EC/pH 조정에 따른 생육 반응 등을 가상 환경에서 사전에 시험할 수 있다. 또한 상관관계 분석 및 특성 중요도 해석을 제공함으로써 예측 결과의 ‘이유’를 설명하고, 현장 의사결정 과정에서의 신뢰도를 높이는 데 기여한다. 교육 측면에서도 신규 인력·학생에게 온실 제어와 생육 반응의 관계를 3D 환경에서 학습시키는 데 활용 가능하다.
5. 논 의
본 연구는 디지털 트윈 기반 동기화와 메타버스 상호작용, 그리고 XGBoost 기반 예측 모델을 통합함으로써 기존 ML 기반 농업 예측/시뮬레이션과 차별화된다. 기존 연구가 예측 성능 보고에 머물러 실제 운영 지원 체계가 약했던 반면, 본 연구는 사용자 상호작용(조건 조작→예측 비교→의사결정)을 시스템 수준에서 구현했다는 점에서 기여가 있다.
정량 성능 결과에서 착과수(frtstCo)와 엽수(lefCunt)가 상대적으로 높은 설명력을 보인 것은, 이 지표들이 입력 변수(온도·CO₂·일사량 등) 변화에 보다 직접적으로 반응하거나, 데이터 측정이 비교적 안정적이었을 가능성을 시사한다. 반면 생장길이(grwLt), 줄기굵기(stemThck) 등에서 R²가 낮거나 음수로 나타난 것은 모델의 일반화 한계와 데이터 특성의 영향이 복합적으로 작용했을 수 있다. 음의 R²는 예측 성능이 ‘평균값 예측’ 보다도 낮을 수 있음을 의미하며, 통상적으로 (1) 변수 반응의 비선형·지연 효과, (2) 누락 변수(외기 조건, 관리 이벤트), (3) 센서 품질/결측 구간, (4) 표본 수 부족, (5) 동별 분포 차이 등이 원인으로 제시될 수 있다. 따라서 향후 연구에서는 입력 변수 확장(외기, 작업 이벤트, 병해충 등)과 장기 데이터 축적을 통해 성능 개선 가능성을 검토할 필요가 있다.
또한 3개 온실 동 전체 결과를 제시하고 통계 검정을 수행한 점은, 단일 사례 중심의 편향을 줄이고 효과성을 엄밀하게 검증하려는 시도라는 점에서 의의가 있다. 다만 본 연구의 통계 검정은 요약 수준으로 제시되었으며, 향후에는 지표별 p-value와 효과크기(effect size), 신뢰구간(confidence interval), Bland–Altman 분석 등 보다 다양한 검증 프레임을 적용하면 신뢰도를 추가로 높일 수 있다.
실무 적용 관점에서 본 시스템은 시행착오 비용 감소와 조기 이상 탐지에 기여할 수 있다. 예컨대 특정 조건 변경의 효과를 사전에 실험함으로써 불필요한 에너지·자원 투입을 줄이고, 생육 이상 징후를 조기에 탐지하여 품질 저하 및 수확량 변동 리스크를 완화할 수 있다. 다만 시스템 도입을 위해서는 데이터 인프라(센서 품질, 수집 주기, 표준화)와 운영 프로세스(의사결정 루프)가 함께 정착되어야 한다.
마지막으로 본 연구는 교육·훈련 확장성 측면에서도 의의를 갖는다. 메타버스 환경은 현장 접근이 어려운 상황에서도 온실 제어와 생육 반응을 반복 학습할 수 있게 하며, 이는 신규 인력 양성과 교육 콘텐츠 개발에 활용 가능하다. 향후에는 사용자 실험(사용성 평가, 학습효과 측정)을 추가하여 교육적 효과를 실증적으로 검증할 필요가 있다.
6. 결 론
본 연구는 디지털 트윈과 메타버스를 통합한 농업 메타버스 시뮬레이터를 개발하고, XGBoost 기반 회귀 예측 모델을 결합하여 그 효과성을 정량적으로 검증하였다.
데이터 측면에서는 입력 7종(재배주차, 내부온도, 내부습도, CO₂, 누적일사량, EC, pH)과 출력 11종(생장길이, 엽수, 엽장, 엽폭, 화방높이, 줄기굵기, 개화화방, 개화군, 착과군, 수확군, 착과수) 총 18개 변수를 구성하였고, 단위 통일, 결측치 처리, IQR 기반 이상치 제거/보정 기준을 명시함으로써 데이터 전처리 과정의 투명성을 확보하였다. 예측 성능 평가는 회귀 모델 핵심 지표인 RMSE와 R²를 사용하여 정량적으로 제시하였으며, 온실 동(farm_code)별 결과를 함께 제공하여 특정 사례에 편향되지 않도록 구성하였다. 정량 결과에서 착과수(frtstCo)와 엽수(lefCunt)는 비교적 높은 설명력을 보여, 본 시스템이 일부 핵심 지표에 대해 실무적으로 의미 있는 예측 가능성을 갖는다는 점을 확인하였다. 반면 생장길이(grwLt), 줄기굵기(stemThck) 등 일부 변수에서는 낮거나 음의 R²가 나타나 데이터 변동성, 누락 변수, 학습 범위 제한 등으로 인한 일반화 한계가 존재함을 확인하였다. 이는 본 연구의 한계이자 향후 개선 방향을 명확히 제시하는 결과로, 입력 변수 확장(외기, 관리 이벤트, 병해충 등)과 장기·대규모 데이터 축적이 후속 연구에서 중요함을 시사한다.
효과성 검증 측면에서 본 연구는 실증 재배 온실 3개 동 전체 결과를 제시하고, 시뮬레이션과 실측 간 차이에 대한 통계적 유의성 검정(대응표본 t-검정, 필요 시 비모수 검정)을 포함하여 검증의 엄밀성을 강화하였다. 특히 1동에서 약 90% 수준의 일치 경향이 보고되었고, 2동과 3동에서도 유사한 추세가 관찰되어 디지털 트윈 기반 시뮬레이터가 실측 환경을 합리적 수준에서 재현할 수 있음을 뒷받침하였다. 다만 통계 검정 결과의 세부 지표별 p-value, 효과크기, 신뢰구간 등을 추가로 제시하면 해석의 객관성과 설득력을 더 높일 수 있으므로, 후속 연구에서 이를 보완할 필요가 있다.
종합하면, 본 연구는 (1) 디지털 트윈 기반 동기화, (2) 메타버스 기반 상호작용, (3) ML 기반 예측을 통합한 농업 시뮬레이터를 제안하고, 실증 데이터 기반 정량 평가를 통해 적용 가능성과 한계를 동시에 제시하였다. 본 시스템은 농가 운영 측면에서 시나리오 기반 사전 실험을 통해 시행착오 비용을 줄이고, 환경 제어 전략을 합리적으로 검토하는 데 활용될 수 있으며, 교육·훈련 측면에서도 3D 환경에서의 반복 학습을 통해 이해도를 높일 수 있다. 향후에는 다양한 작물·지역·재배 방식으로 확장하고, 사용자 실험을 통한 사용성 및 교육 효과 평가를 결합함으로써 현장 적용성을 한층 강화하는 것이 과제로 남는다.
