

1. 서 론
2. 이론적 배경
2.1. Artificial Neural Network
2.2. Dropout
3. 연구 방법
3.1. 수집한 데이터의 종류와 특성
3.2. 데이터 전처리
3.3. 평가지표
3.4. Case 선정
3.5. 분석 방법
4. 결과 및 분석
4.1. Case별 CV(RMSE) 비교
4.2. Case 및 시간대별 오차 값 분석
4.3. Case별 신뢰구간 및 평균 오차 비교
5. 추가 분석
6. 결 론
1. 서 론
기후 변화의 영향으로 재생에너지는 에너지 산업에서 중대한 패러다임 전환을 가져오고 있다. IEA에서 발표한 2023 Renewable report에 따르면 두바이에서 열린 COP28 기후 정상 회담에서 2030년까지 전 세계 재생에너지를 2023년 대비 발전 용량 3배, 에너지 효율을 2배 늘리는 것을 목표로 하였다(IEA, 2023). 이러한 국제적 목표는 대한민국을 포함한 여러 국가의 에너지 정책에 큰 영향을 미치고 있으며, 대한민국은 2036년까지 신재생 에너지 설비 용량은 108.3GW로 2023년 대비 2.3배 증가시킬 것이라 발표하였다. 발표된 신재생 에너지 용량 중 약 60%가 태양광 에너지로, 향후 빠르게 보급될 것으로 예상된다(MOTIE, 2023). 이처럼 태양광 발전은 친환경적이면서 지속할 수 있는 에너지원으로 주목받고 있으며, 향후에도 빠른 속도로 보급될 것으로 예상된다(Son, 2023). 태양광 발전의 보급이 확대됨에 따라, 발전량 예측의 중요성도 함께 커지고 있다. 정확한 발전량 예측은 전력 가격을 결정하는 중요한 요인 중 하나이며, 전력 공급의 신뢰성을 높이는 데 중요한 역할을 한다. 이에 따라 IEA에서는 태양광 발전기의 발전량 예측을 권고했으며, 대한민국의 경우 2020년 9월부터 관련 제도를 도입하여 태양광 발전량을 예측하고 있다(Lee et al., 2021). 그러나 태양광 발전은 기후 조건과 설비 상태 등의 외부 요인에 민감하게 반응하기 때문에, 더 정교한 예측 모델의 필요성이 대두되고 있으며, 데이터 분석 및 머신러닝 기법을 활용한 태양광 발전 예측 연구가 활발히 이뤄지고 있는 상태이다(Woo, So, Kang, & Sin, 2024). 기존 연구들은 태양광 발전량을 예측하기 위해 여러 AI 기법을 도입하여 데이터 패턴을 인식하고 예측 정확도를 증가시켰다. 예를 들어, Saxena 등(2024)은 KNN-SVM 하이브리드 모델을 통해서 태양광 발전량을 예측하고자 하였다. 해당 모델은 기존 모델 대비 우수한 예측 성능을 나타냈으며, 여러 지역과 기간에 걸쳐 평가를 진행하여 모델의 신뢰성을 확보하였다. Gensler, Henze, Sick와 Raabe (2016)은 LSTM, MLP, DBN 등과 같은 여러 모델을 사용하여 태양광 예측 결과를 비교하였다. 그 결과 사용한 모델 중 특징 추출이 가능한 모델이 태양광 예측이 우수한 것으로 나타났으며, 하나의 모델만 사용하는 것이 아닌 여러 모델의 강점을 활용한 모델을 개발한다면, 더 우수한 태양광 예측이 가능하다고 주장하였다. Tahir, Yousaf, Tzes, El Moursi와 El-Fouly (2024)은 ANN, SVM, GPR 등과 같은 여러 모델을 사용하여 태양광을 예측하였으며, 모델과 더불어 하이퍼 파라미터 최적화를 함께 진행하였다. 그 결과 기존 모델 대비 예측 정확도가 향상하였으며, 하이퍼 파라미터의 최적화가 모델 예측 정확도 향상에 도움이 된다고 주장하였다. Tripathi 등(2024)은 SVMR, GPR과 같은 모델과 Dicky-Fuller, 데이터 세트 교차 검증을 통하여 태양광 발전량 예측을 하였다. 그 결과 기존 머신러닝 모델의 예측 정확도 대비 뛰어난 성능이 나타났다. 이와 같이, 에너지 산업의 패러다임에 맞춰 기존 연구자들은 다양한 모델의 성능 비교를 통해 높은 예측 성능을 가진 모델을 파악하고 머신러닝 기술의 활용 가능성을 넓히는데 기여했다. 하지만, 기존 연구들은 모델의 성능 향상에 주로 초점을 맞추었으며, 모델의 일반화를 고려한 연구는 상대적으로 부족했다. 모델의 일반화란 기존에 사용하지 않은 새로운 데이터에서도 높은 예측 성능을 유지하는 능력을 말하며, 이는 머신러닝에서 매우 중요한 목표 중 하나이다(Nasiri, Hawryło, Janiec, & Socha, 2023). 이런 모델의 일반화와 반대되는 개념 중 하나인 과적합은 머신러닝에서 흔히 발생하는 어려움 중 하나로 훈련 데이터에 지나치게 의존하여 테스트 데이터를 예측하지 못하게 되는 현상을 의미하며, 이는 모델 신뢰성 저하를 의미한다(Ying, 2019).
이에 따라 본 연구에서는 태양광 발전량 예측에서 모델의 일반화 능력을 높이기 위해 Dropout 기법을 적용하고 그 효과를 분석하고자 한다. Dropout은 학습 과정에서 뉴런의 일부를 무작위로 비활성화함으로써 과적합을 방지하고, 모델의 예측 능력을 향상 시키는 정규화 기법이다. 본 연구는 Dropout을 적용한 모델과 그렇지 않은 모델 간의 성능을 비교하여, 더 일반화된 예측 모델을 개발하는 데 목적을 두고 있다.
2. 이론적 배경
2.1. Artificial Neural Network
Artificial Neural Network(ANN)은 생물학적 신경망을 모델링한 수학적 구조로, 입력 데이터로부터 최적의 패턴을 학습할 수 있으며, 일반적으로 입력층, 은닉층, 출력층으로 구성되어 있다. 입력층 또는 이전 층의 결과 값을 각 가중치와 함께 계산한 후 활성화 함수 연산을 통해 결과 값을 도출한다. 도출된 출력은 다음 층의 계산에 다시 사용된다. 또한 ANN은 복잡한 모델에서도 우수한 성능을 나타낼 수 있다는 장점과 최적 값을 찾는 과정에서 Gradient vanishing, 과적합 현상에 취약하여, 이는 모델의 예측 성능을 저하시킬 수 있다(Park, Hong, Yeon, Seo, & Lee, 2023).
2.2. Dropout
Dropout은 2.1에서 언급한 과적합 문제를 해결하기 위한 기법 중 하나로 Geoffrey hinton에 의해 제안된 정규화 기법이다. 학습 과정에서 특정 뉴런을 무작위로 제거(drop)하여 과적합을 방지하는 효과적인 방법으로 알려져 있다. Dropout은 각 학습 단계에서 일부 뉴런을 임시적으로 제거함으로써 모델의 구성을 다양화하고, 이를 통해 새로운 데이터에 대한 일반화 능력을 향상 시킬 수 있다. 그러나 Dropout 비율이 너무 많은 경우 모델의 학습 과정이 안정적이지 못하고 예측 성능이 저하될 수 있으며, Input unit의 경우 20%의 비율이 가장 뛰어난 것으로 나타났다(Hinton, Sricastava, Krizhevsky, & Salakhutdinov, 2012; Srivastava, Hinton, Krizhevsky, Sutskever, & Salakhutdinov, 2014).
3. 연구 방법
3.1. 수집한 데이터의 종류와 특성
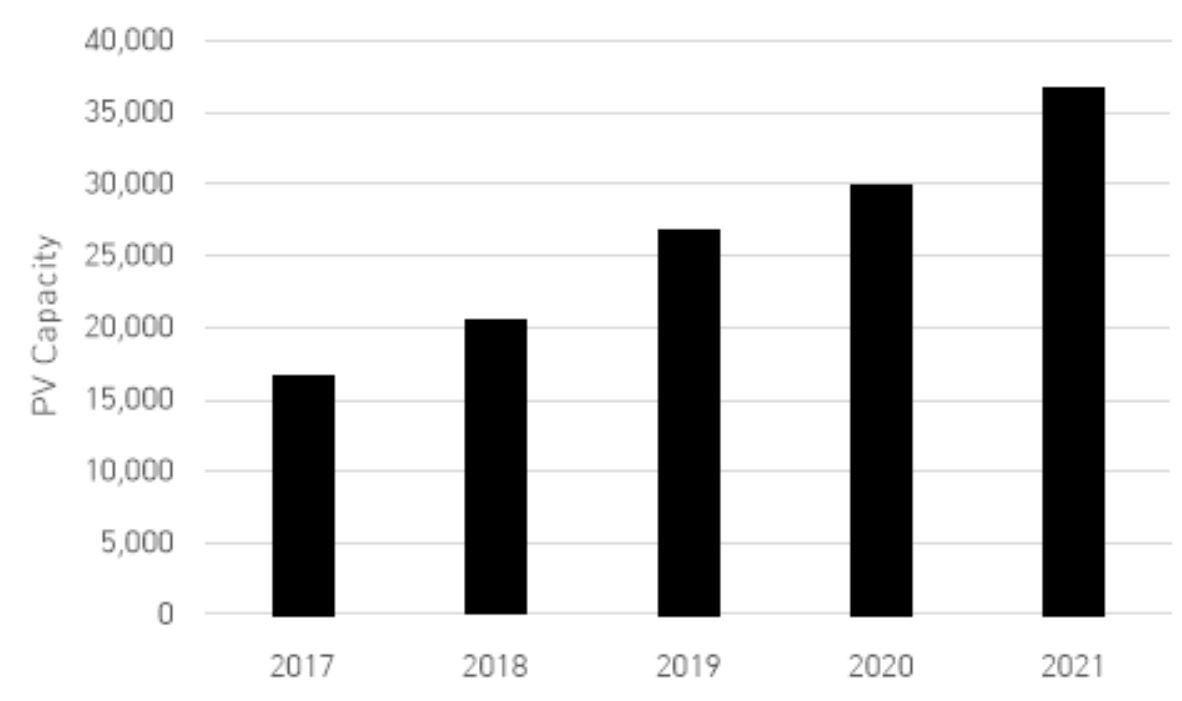
본 연구에서는 대전지역의 2017.01.01. ~ 2021.12.31.의 기상 데이터, 태양광 발전 용량 및 전력 거래량 데이터는 각각 기상청 종관센터, 대전시, 전력거래소에서 제공받았다. 또한 2017.01.01. ~ 2020.12.31을 학습, 2021.01.01. ~ 2021.12.31.을 테스트 기간으로 설정하였다. Pearson Correlation Coefficient(PCC)를 통하여 입력과 출력 변수의 관계를 살펴보았으며, 이를 통해 선정한 변수는 Table 1과 같으며, 태양광 발전 용량은 Figure 1과 같다. 대전지역의 경우, 시간이 지남에 따라 설치된 태양광 발전 용량이 증가하였고, 이러한 용량 증가는 태양광 발전량에 직접적인 영향을 미쳤다. 이에 따라, 5년간의 용량 변화를 고려하여 전력 거래량을 조정하였다.
Table 1.
PCC with Input and Output Variables
3.2. 데이터 전처리
본 연구에서는 데이터의 품질을 높이고 모델 학습 효율성을 극대화하기 위하여 전처리를 진행하였다. MinMaxScaler를 통하여 데이터 정규화를 진행하였다. MinMaxScaler는 데이터셋을 0에서 1사이의 범위로 변환하였으나, 해당 정규화는 StandardScaler와 마찬가지로 이상치 값에 매우 민감하다는 단점에 존재한다(Scikit-learn, 2022). 이러한 문제점을 해결하기 위하여 수집한 데이터 중 Output 변수를 기준으로 이상치 를 제거하였다. 이상치 판단 기준으로는 Z-score가 3 이상인 경우로 하였으며, 좌측 검정을 기준으로 하였다. 그 결과 수집된 데이터 43,824개의 데이터 중 2%에 해당하는 879개의 데이터를 이상치로 판단하여 학습에 제외한 42,945개의 데이터만을 사용하였다. 이는 학습 데이터의 편향을 최소화하고 일반화된 모델을 구축하기 위함이다.
3.3. 평가지표
본 연구에서는 개발될 모델의 예측 성능을 평가하기 위하여 CV(RMSE)와 신뢰구간을 사용하였다. CV(RMSE)는 모델의 예측 정확도를 나타내는 지표로서, 비교적 직관적이고 명확한 성능 평가를 가능하게 한다. 해당 평가 지표는 ASHRAE Guideline 14에서 권장하는 방법으로 신뢰할 수 있는 평가 기준을 제공한다. 특히, 1시간 단위로 수집된 데이터를 사용하는 경우, CV(RMSE) 값이 30% 이하인 경우에 모델의 예측 성능이 만족스럽다고 평가되며, 이는 수식 (1), (2)와 같다(A.S.H.R.A.E, 2014).
신뢰구간이란 통계학에서 표본을 사용하여 모집단의 특성을 추정할 때 생기는 오차의 위험 정도를 측정하기 위해 사용하는 방법이다. 신뢰수준은 통계학에서 일반적으로 사용되는 95%를 기준으로 하였으며, 그에 따른 유의수준은 5%이다(Riffenburgh, 2012; Lin, Wang, Cheng, Liu, & Chen, 2023).
3.4. Case 선정
본 연구에서는 Dropout 기법의 적용 여부 및 그 비율이 머신러닝 모델의 성능에 미치는 영향을 분석하기 위해 세 가지 실험 Case를 설정하였다. 각 Case는 동일한 데이터셋과 학습 조건을 기반으로 하였으며, Dropout 비율은 각각 0%, 10%, 20%로 설정하였다.
Case 1 : Dropout 기법을 적용하지 않은 모델
Case 2 : Dropout 비율 10%를 적용한 모델
Case 3 : Dropout 비율 20%를 적용한 모델
각 Case는 동일한 데이터셋 및 학습 조건을 기반으로 평가하였다. 학습 조건은 다음과 같다: Hidden layer는 1 ~ 2, Hidden node는 10 ~ 15, Epoch = 100으로 설정하였다. 이를 통해 Dropout 기법과 비율이 모델의 성능 및 일반화 능력에 미치는 영향을 체계적으로 평가하고자 한다.
3.5. 분석 방법
각 Case에 대해 예측 성능을 비교하고, 시간대별 오차 분석을 수행하였다. 이를 통해 Dropout 적용 유무와 비율에 따른 예측 정확도의 차이를 분석하였다. 특히, 시간대별 오차 분석을 통해 모델의 예측 성능이 특정 시간대에 따라 어떻게 달라지는지 파악하였다. 또한, 신뢰구간과 평균 오차 값을 비교하여 모델의 안정성과 예측 정확성을 종합적으로 평가하였다.
4. 결과 및 분석
4.1. Case별 CV(RMSE) 비교
본 연구에서는 앞서 설정한 세 가지 Case(Case 1: Dropout 비율 0%, Case 2: Dropout 비율 10%, Case 3: Dropout 비율 20%)에 대해 예측 성능을 비교하였으며, 이는 Figure 2, 3, 4, Table 2와 같다. 각 Case의 예측 성능은 CV(RMSE)와 ASHRAE Guideline 14를 기준으로 평가되었다. 모든 Case에서 CV (RMSE) 값은 30% 이하로 나타나, 예측 성능이 기준을 충족하는 것으로 나타났다. Case 2는 CV(RMSE) 값이 29.31로 가장 우수한 성능을 보였으나, Case 1(29.32) 및 Case 3(29.37) 와의 성능 차이는 미미하였다. 따라서, Dropout 비율의 변화가 예측 성능에 큰 영향을 미치지 않았다는 점을 확인할 수 있다. 이는 Dropout 기법이 과적합 방지에 유효할 수는 있으나, Dropout 비율이 지나치게 높거나 낮은 경우 성능에 유의미한 개선이 없을 수 있음을 시사한다.
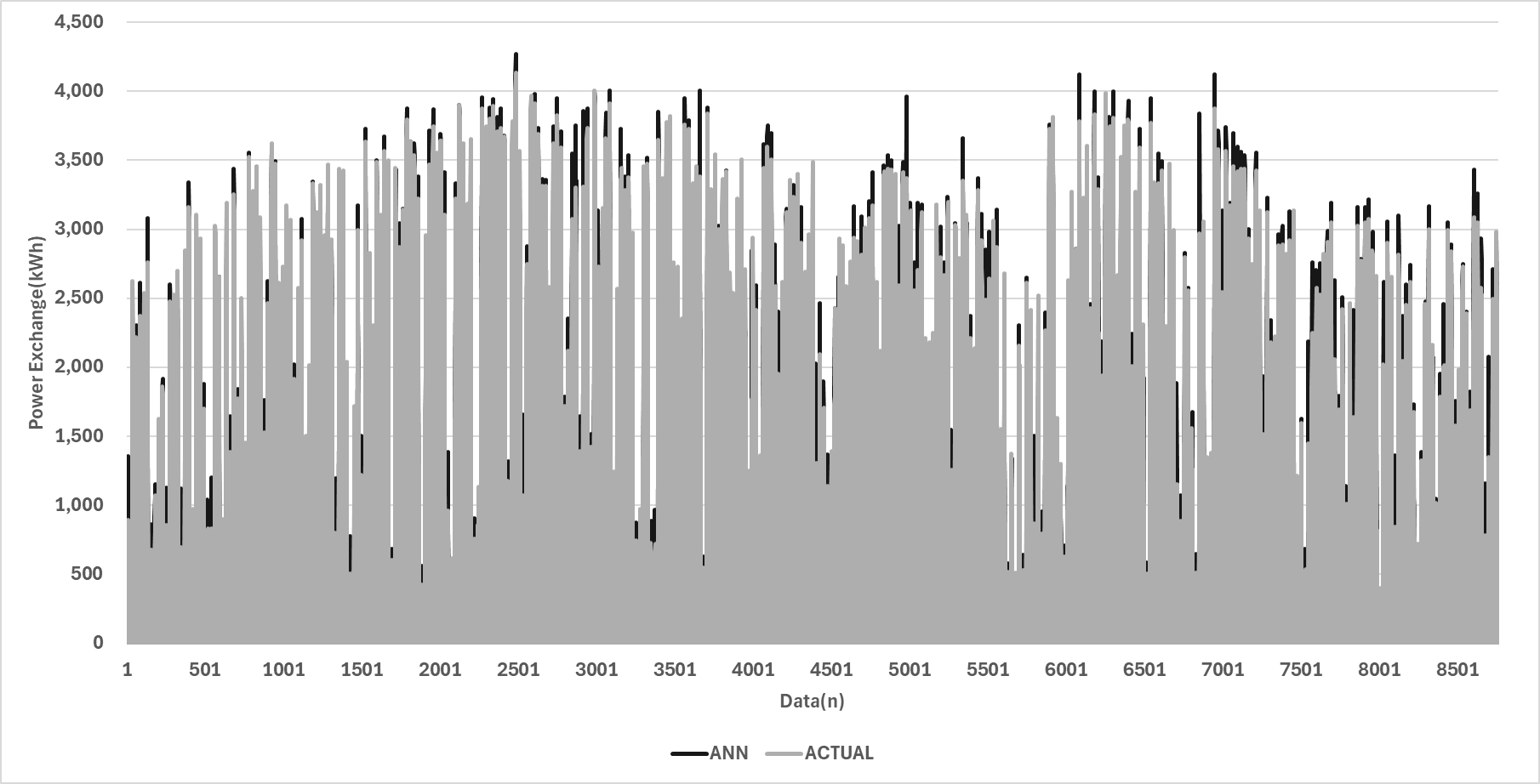
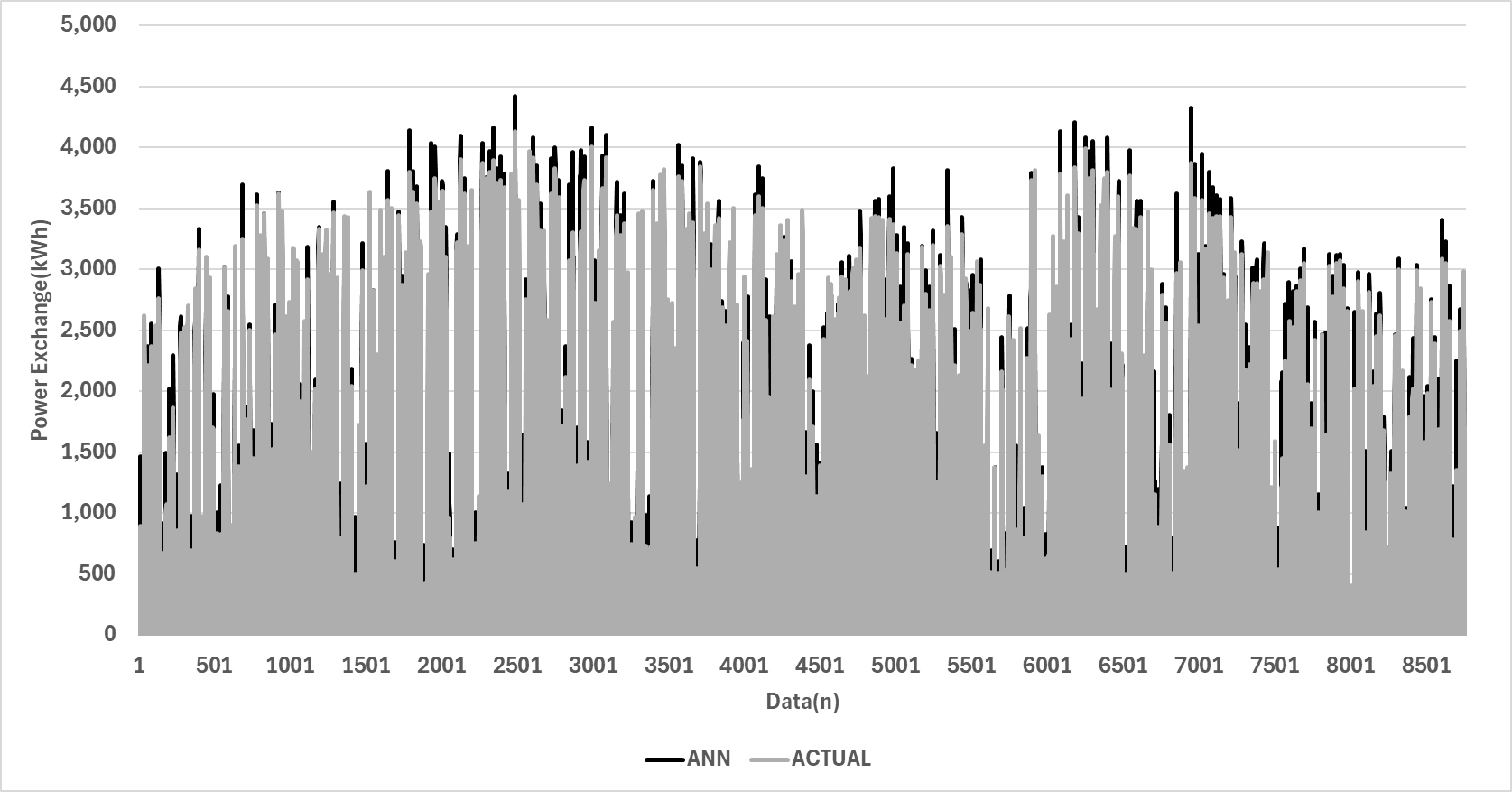
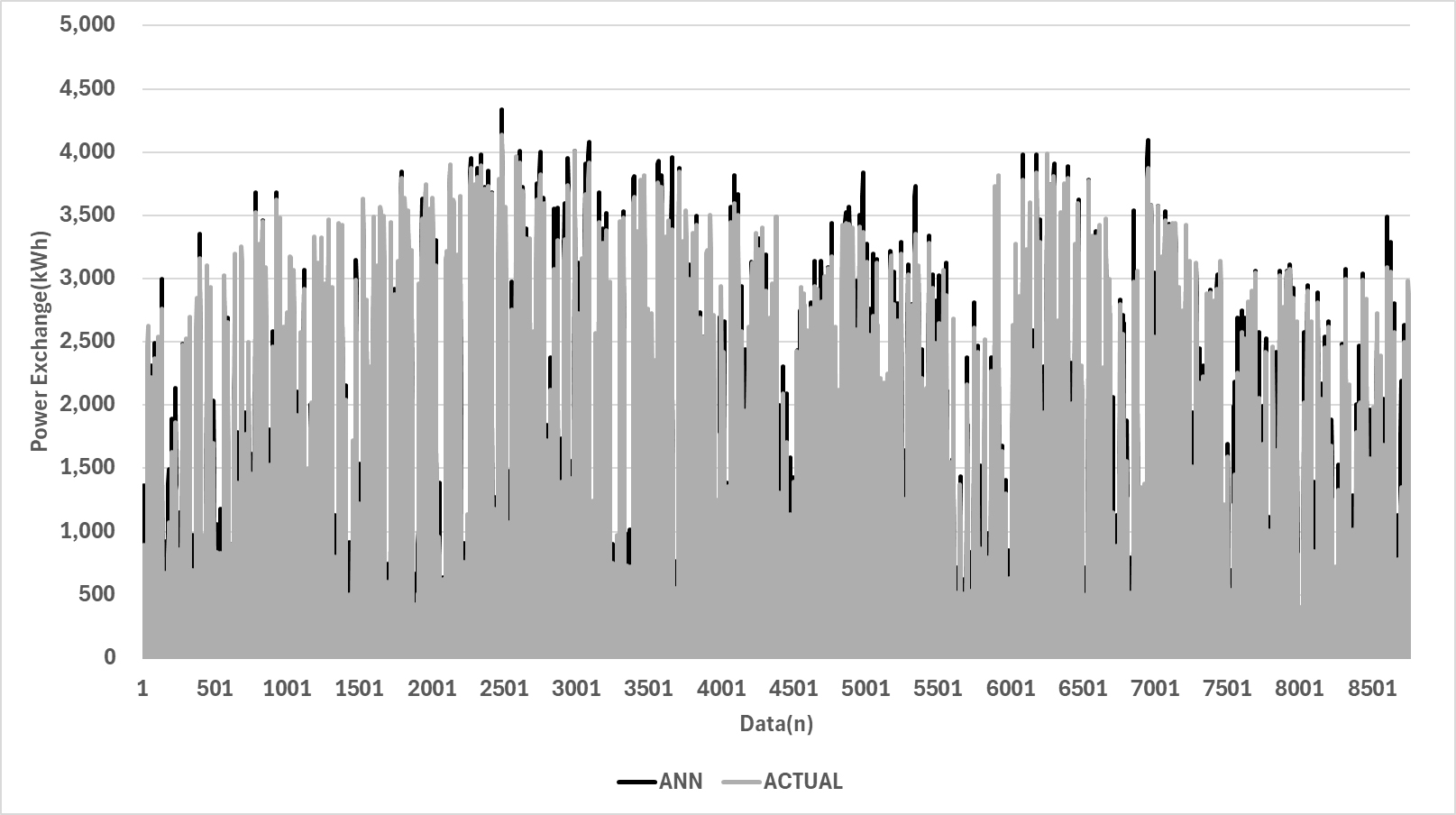
Table 2.
Optimal Structure and Model Performance by Case
| Case | Dropout rate (%) | Hidden layer (n) | Hidden node (n) | CV(RMSE) (%) |
| 1 | 0% | 2 | 13,12 | 29.32 |
| 2 | 10% | 15,14 | 29.31 | |
| 3 | 20% | 15,14 | 29.37 |
4.2. Case 및 시간대별 오차 값 분석
본 연구에서는 시간대별로 각 Case의 오차 값을 최소, 평균, 최댓값으로 구분하여 분석하였다. Figure 5의 경우 시간대별 오차의 최솟값을 나타낸다. Case 1은 대부분의 시간대에서 Case 2 및 Case 3보다 높은 오차를 나타냈다. 특히, 20시 이후에는 오차가 급격히 증가하는 경향이 보였다. 이는 Case 1이 다른 두 Case에 비해 전반적인 예측 성능이 떨어짐을 의미한다. 반면, Case 2의 경우 시간에 따른 변동성이 적어 모델의 일반화 능력이 상대적으로 우수한 것으로 나타났다. Case 3의 경우 초기 오차는 특정 시간대에서 급격하게 증가하는 패턴이 나타났다. 이는 조건에 따라 모델의 성능 일정하지 않을 수 있음을 의미한다.
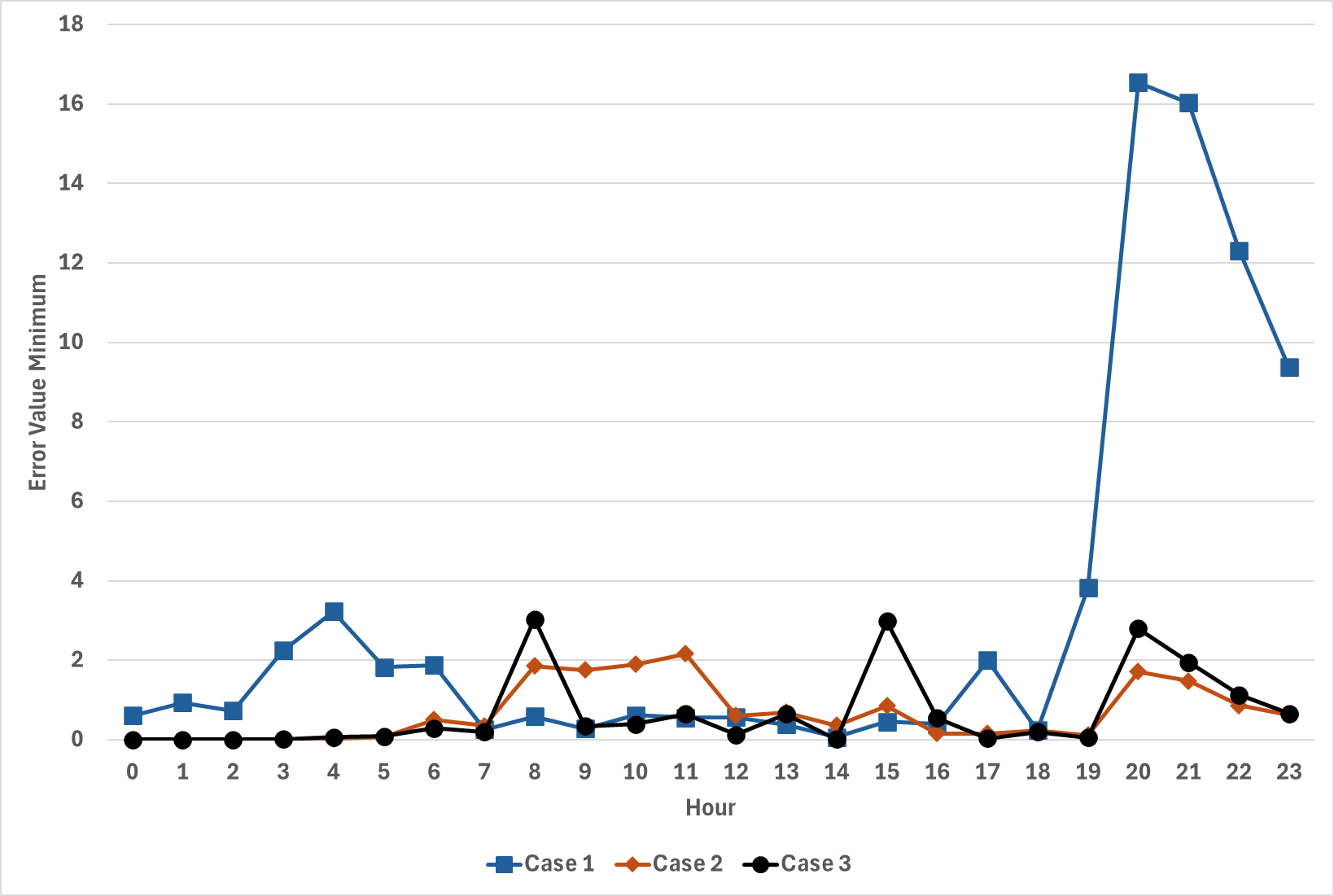
Figure 6의 경우 시간대별 오차의 평균값을 나타낸다. Case 1의 경우 대부분의 시간대에서 비슷한 형태를 나타내고 있으나, 일몰 시간대인 19시부터 오차 값이 상대적으로 크게 발생하였다. Case 2의 경우 9시부터 12시까지 Case 2에서 상대적으로 큰 오차를 나타내어, 특정 시간대에서 예측 성능이 저하될 가능성이 있음을 시사한다. Case 3의 경우 상대적으로 낮고 안정적인 오차를 유지하고 있으며, 다른 Case 대비 예측의 일관성이 높은 것으로 나타났다.
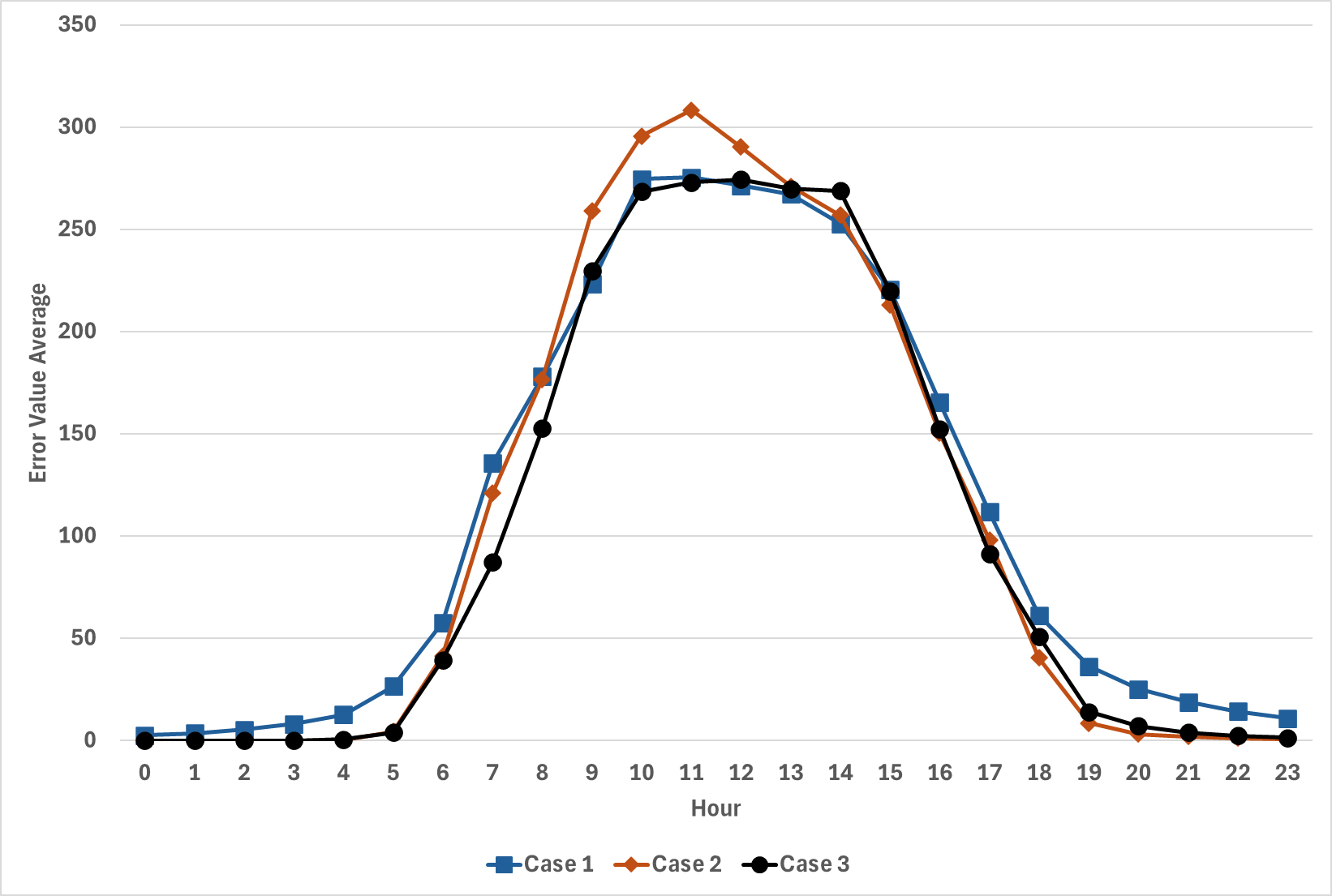
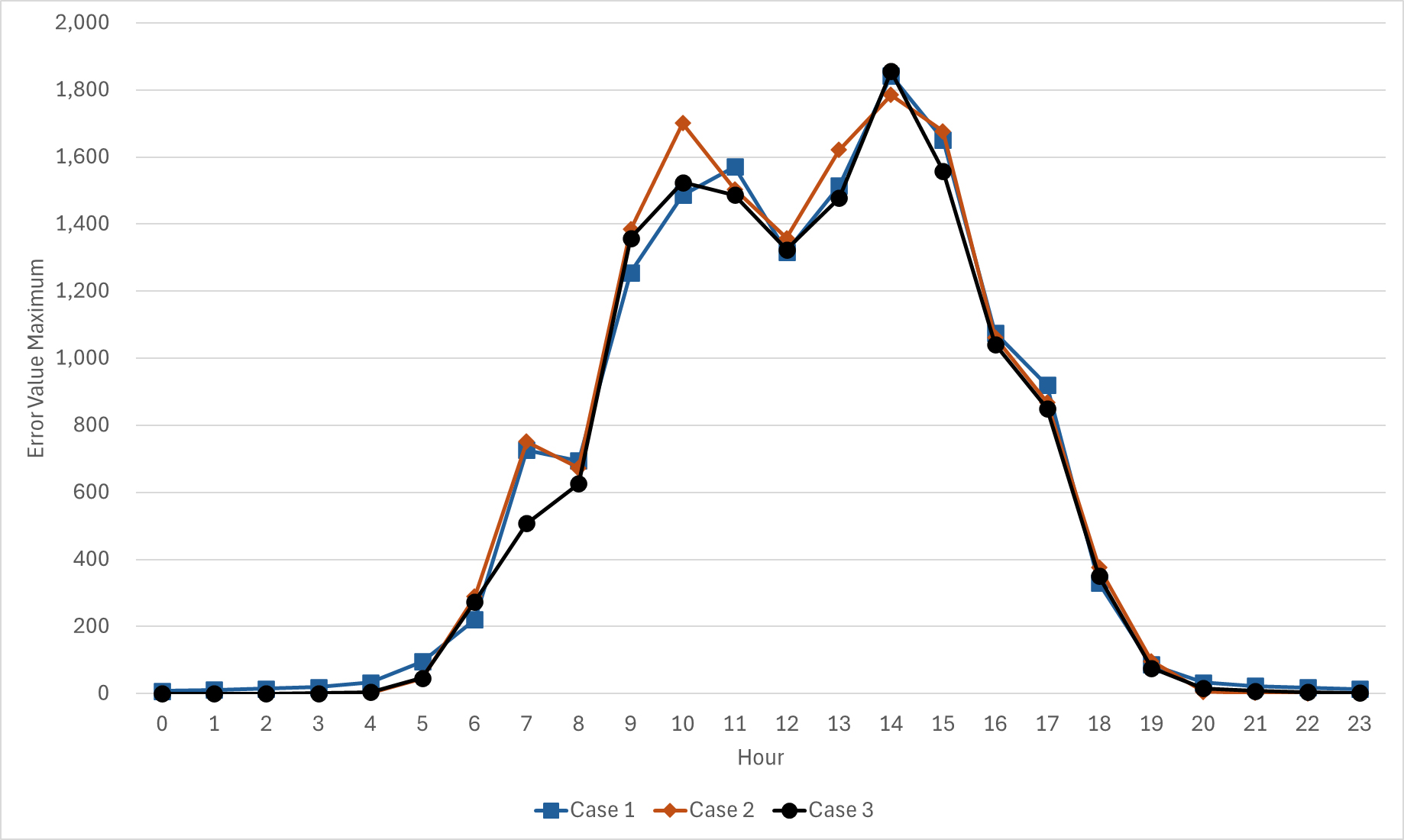
Figure 7의 경우 시간대별 오차의 최댓값을 나타낸다. 모든 Case에서 14시에 가장 큰 오차가 발생하였으며, 이는 각 모델이 특정 시간대에서 예측 정확도가 떨어질 수 있다는 것을 시사한다. 특히, 일출 시간인 7시부터 8시의 급격한 오차 증가에도 Case 3의 경우 다른 Case보다 안정적인 오차 값을 유지하여, 특정 시간대에서의 예측 안정성이 상대적으로 높음을 나타냈다. 이는 Figure 5에서 언급한 바와 같이 Case 3의 경우 일출 및 일몰 시간대에서 상대적으로 안정적인 예측이 가능함을 의미한다.
4.3. Case별 신뢰구간 및 평균 오차 비교
본 연구에서는 각 Case의 신뢰구간(95%)과 평균 오차를 비교하였다. 신뢰구간은 Table 3과 같으며, 신뢰구간의 폭은 Case 2 – Case 1 – Case 3의 순으로 나타났다. 가장 좁은 신뢰구간을 나타낸 Case 3의 경우 모델의 예측 정확도가 가장 높을 가능성이 있음을 의미한다. Case 1이 Case 2 대비 좁은 신뢰구간을 나타내 상대적으로 예측 정확도가 뛰어날 가능성이 높은 모델이라 판단할 수 있다. 그러나, 테스트 기간 전체의 평균 오차 값은 Case 1 : 110.84 kWh, Case 2 : 105.97 kWh, Case 3 : 100.5 kWh로 신뢰구간 폭과는 다소 다른 결과가 나타났다. 이는 단순히 신뢰구간의 폭만으로 모델의 성능을 평가하는 데 한계가 있음을 나타냈다. 결과를 종합적으로 고려했을 때, Case 3이 가장 안정적이고 일관된 예측 성능을 보이는 것으로 평가되어 Dropout 비율이 적절히 설정되었을 때, 모델의 예측 정확성과 신뢰성을 동시에 향상시킬 수 있음을 의미한다.
5. 추가 분석
본 연구에서는 CV(RMSE) 값이 예상보다 높은 이유를 데이터의 경향성과 모델의 제한점을 통해 설명하고, 모델 성능 개선 방향을 제시하고자 한다. 학습 데이터로 2017년 1월 1일부터 2020년 12월 31일까지, 테스트 데이터로 2021년 1월 1일부터 2021년 12월 31일까지의 데이터를 사용하였다. 이 기간 동안 대전 지역의 태양광 발전량은 감소하는 추세를 보였다. 시간별 평균 발전량은 Table 4에 나와 있으며, 학습 기간의 평균 발전량은 1720.65 kWh였다. 반면, 테스트 기간에는 약 25% 감소한 발전량을 기록하였다.
Table 4.
Confidence interval (95%) width by case
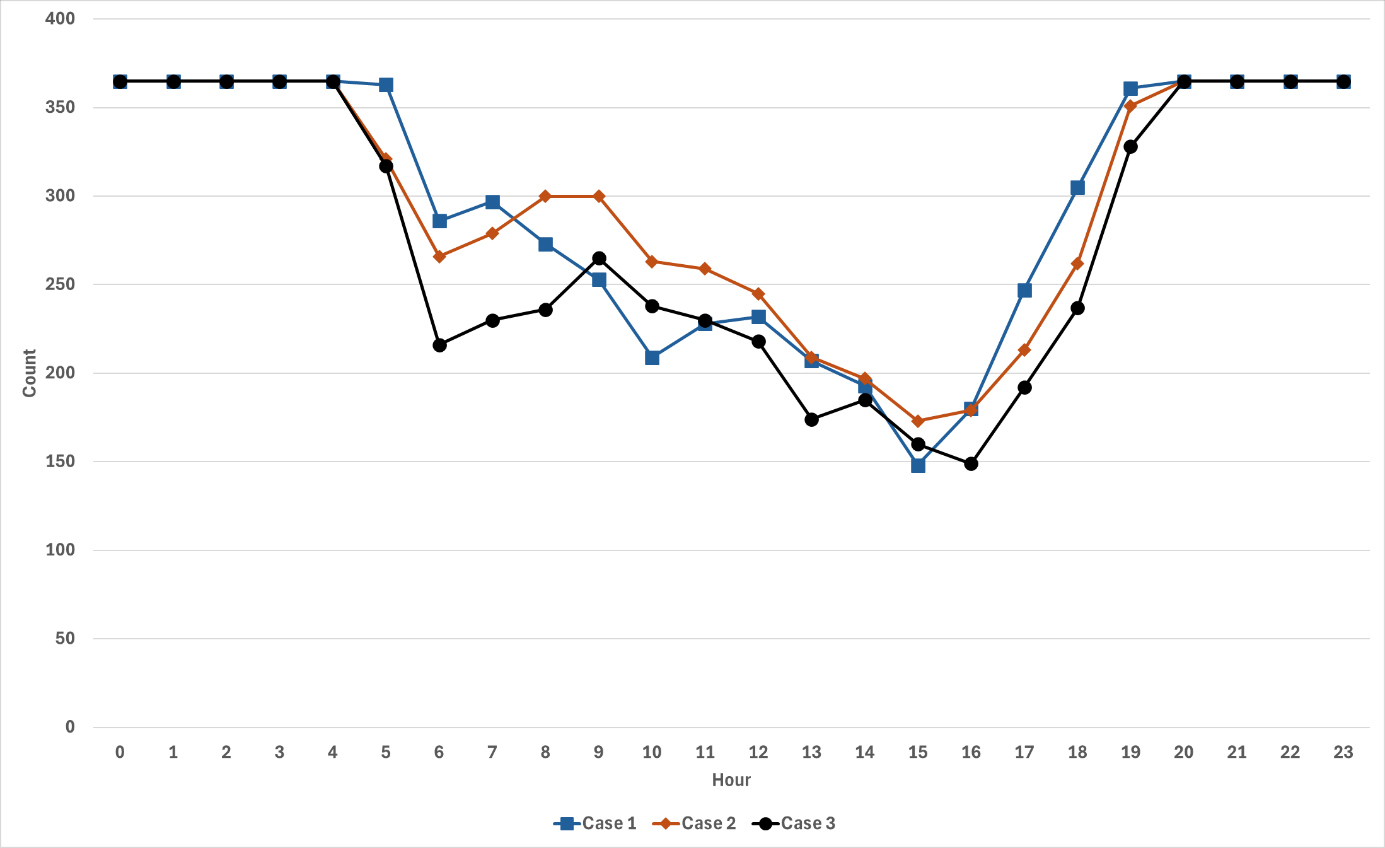
일반적인 머신러닝 모델은 과거 데이터를 기반으로 학습 및 예측을 하기 때문에, 이러한 발전량의 변화를 절절히 반영하지 못할 수 있다. Figure 8에 나타난 바와 같이, 대부분의 시간대에 예측값이 실측값보다 높게 나타났다. 이는 2021년도의 태양광 발전량 감소 추세와 태양광 시스템 효율 등을 제대로 반영하지 못했음을 시사한다. 추후 연구에서는 이러한 문제점을 방지하기 위하여 시계열 데이터 분석 기법을 도입하고자 한다. 예를 들어, 계절적 변동성 제거 및 이상치 처리를 강화하여 데이터 전처리 과정을 개선할 필요가 있다. 또한, 비정상 데이터 패턴 학습을 위한 비지도 학습 또는 강화 학습 기법을 적용하여 향상된 예측 성능을 도모할 수 있다. 이러한 방법들은 비록 초기 설정이 복잡할 수 있으나, 변화하는 발전량 패턴을 효과적으로 반영할 수 있을 것으로 보인다.
6. 결 론
본 연구에서는 Dropout 기법의 유무 및 비율에 따른 예측 성능을 비교하고, 이를 통해 모델의 일반화를 확보하는 것에 중점을 두고 있다. 모든 Case에서 모델의 예측 성능이 기준을 충족하였으나, Dropout 비율의 변화에 따른 성능 차이는 미미했다. 다만, 적절한 Dropout 비율을 적용했을 때 예측 평균 오차 값은 Case 3의 경우 Case 1 대비 10.34 kWh 더 낮은 것으로 나타나 모델의 예측 안정성이 향상되는 경향이 관찰되었으며, 이는 모델의 과적합을 방지하는 데 긍정적인 영향을 미쳤다.
시간대별 오차 분석 결과, Dropout을 적용한 모델이 특정 시간대에서 더 안정적인 성능을 보였으며, 신뢰구간 분석에서는 단일 지표로는 모델의 성능을 완벽히 평가하기 어렵다는 점이 드러났다. 따라서 본 연구는 머신러닝 모델의 일반화 성능을 높이기 위해 Dropout 기법의 적절한 활용이 중요하며, 다양한 정규화 기법과의 비교 연구가 필요하다는 결론을 도출하였다. 추후 연구에서는 Dropout 기법 외 다양한 정규화 기법의 비교 분석과 더불어 시계열 데이터 분석 기법을 도입하여 모델의 장기적 예측 성과를 향상시키고자 한다.
그러나 본 연구는 과거 데이터만을 기반으로 하였기에 미래의 변동성을 충분히 반영하지 못했다는 한계와, 기상청 및 전력거래소 등에서 제공받은 데이터만으로는 설비의 문제를 완전히 해결하기 어려웠다는 제한이 있다. 따라서 향후 연구에서는 보다 다양한 데이터 소스를 통합하고, 설비 상태를 고려한 고급 데이터 전처리 방법을 사용하여 이러한 한계를 극복할 필요가 있다. 이를 통해 태양광 발전량 예측 모델이 더욱 신뢰성 있고 유연하게 발전할 수 있을 것이다.
